一维随机变量及其分布
随机变量及其分布函数
随机变量(Random Varible的概念
- 设随机试验\(E\)的样本空间为\(\Omega\),对每一个样本点\(\omega \in \Omega\),均有惟一确定的实数\(X\)与之对应,则称\(X\)为一个定义在\(\Omega\)上的随机变量
- 记作\(X=X( \omega )\)
- 通常随机变量使用\(X,Y,\eta\)等符号表示

- 可以利用随机变量的某种逻辑关系表示随机事件
- 设\(X\)为一随机变量,\(L\)为某实数集,则\(\{X\in L\}\)表示随机事件
- \(\{a<X\le b\},\{X<b\}\)
- 若\(\{-\infty < X < +\infty\}\),则称\(X\)为必然事件
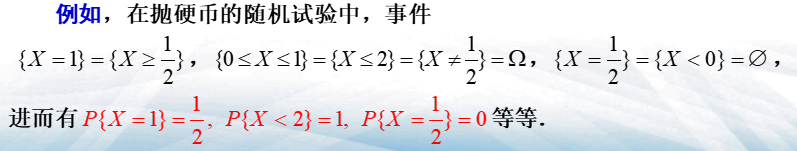
- 设\(X\)为一随机变量,\(L\)为某实数集,则\(\{X\in L\}\)表示随机事件
- 引入随机变量的意义:借助微积分方法将讨论进行到底
- 随机变量的分类:

#概率论重点 分布函数
-
\(X\)为一随机变量,对于任意实数\(x\),称函数\(P\{X\le x\}\)为\(X\)的分布函数,记为\(F(x)\),即随机变量\(X\)的分布函数为:\(\(F(x)=P\{X\le x\},-\infty < x <+\infty\)\)
[!注] - 不论随机变量\(X\)如何取值其分布函数\(F(x)\)的定义域总是\((-\infty,+\infty)\) - 分布函数\(F(x)\)的直观意义为随机变量\(X\)落在区间\((-\infty, x]\)上的概率
-
使用分布函数表示概率
- \(P\{a<X\le b\}=P\{X\le b\}-P\{X \le a\}=F(b)-F(a)\)
- \(P\{X>a\}=1-P\{X\le a\}=1-F(a)\)
- \(P\{X=a\}=F(a)-F(a-0)\)
- 基本性质
- \(0\le F(x) \le 1\)
- \(\lim_{x\to -\infty}F(x)=0,\lim_{x\to +\infty}F(x)=1\)
- \(F(x_0+0)=\lim _{x\to x_0^+}F(x)=F(x_0)\)
- 单调性
- eg:

离散型随机变量及其分布律
离散型随机变量及其分布律的概念
- 离散型随机变量:随机变量\(X\)的取值可以为有限个或可列无限多个
- 离散型随机变量\(X\)的分布律或概率分布:\(P\{X=x_i\}=p_i, i=1,2,...\)
- 表示方法:
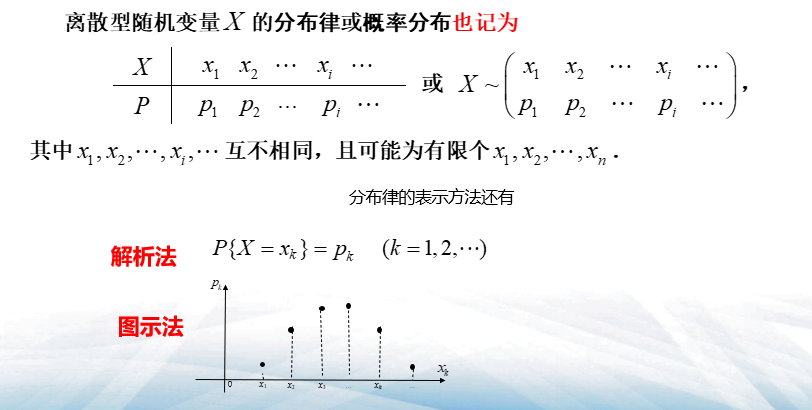
- 表格法\(\(X\sim\begin{pmatrix}x_1&x_2&...&x_i&...\\p_1&p_2&...&p_i&...\end{pmatrix}\)\)
- 解析法
- 图示法
- 离散型随机变量分布律的性质
- \(p_i \ge 0, i=1,2,..\)
- \(\sum_{i}p_i=1\)
- \(P\{X\in L\}=\sum_{x_i \in L}p_i\)
- \(F(x)=P\{X\le x\}=\sum_{x_i\le x}p_i, -\infty<x<+\infty\)
几种常见的离散型随机变量的概率分布
- 离散均匀分布\(P(X=k)=\frac{1}{n},k=1,2,...,n\)
-
概率论重点 0-1两点分布\(P\{X=k\}=p^k(1-p)^{1-k},k=0,1,...,0<p<1\)
- 即\(X\sim \begin{pmatrix}0&1\\1-p&p\end{pmatrix}\)
- 记作\(X\sim B(1,p)\)
-
概率论重点 二项分布(伯努利分布)\(P\{X=k\}=C^k_np^k(1-p)^{n-k},k=0,1,2,...\)
- \(\sum^{n}_{k=0}C^k_np^k(1-p)^{n-k}=1\)
- 记作\(X\sim B(n,p)\)(n重伯努利试验)

-
概率论重点 泊松分布\(P\{X=k\}=\frac{\lambda^k}{k!}e^{-\lambda},k=0,1,2,...,\lambda > 0\)
- \(\sum^{\infty}_{k=0}\frac{\lambda^k}{k!}e^{-\lambda}=e^\lambda·e^{-\lambda}=1\)
- 记作\(X\sim P(\lambda)\)
- 一般来说,在一定时间内,"稀有事件”发生的次数\(X\)服从泊松分布
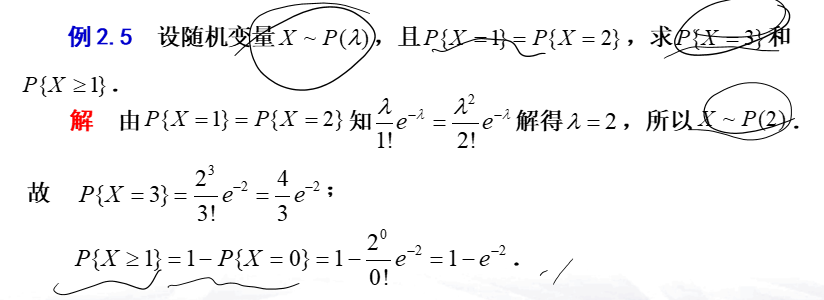
- 泊松定理:在n重伯努利试验中,事件A在每次试验中发生的概率为\(p_n\),且\(p_n\)与试验次数n有关,若\(\lim_{n \to \infty}np_n=\lambda\),则对于任意非负整数k,有\(\lim_{n\to \infty}C^k_np^k_n(1-p_n)^{n-k}=\frac{\lambda^k}{k!}e^{-\lambda}\)

- 泊松分布表
- 几何分布\(P\{X=k\}=(1-p)^{k-1}p,k=1,2,3,...\)
- 记作\(X\sim G(p)\)
- \(\sum^\infty_{k=1}P\{X=k\}=\sum^\infty_{k=1}(1-p)^{k-1}p=\frac{p}{1-(1-p)}=1\)
- 在一系列独立重复实验中,事件A首次发生时所进行的试验次数满足\(X\sim G(p)\)

- 超几何分布\(P\{X=k\}=\frac{C^{n-k}_{N-M}C^k_M}{C^n_N},其中N>1,M\le N,n\le N,\max\{0,M+n-N\}\le k \le \min\{M,n\}\)
- 记作\(X\sim H(M,N,n)\)

- 记作\(X\sim H(M,N,n)\)
连续型随机变量及其密度函数
连续型随机变量及其密度函数的概念
- 分布函数\(F(x)=\int^{x}_{-\infty}f(t)dt\),\(X\)为连续型随机变量,\(f(x)\)为\(X\)的密度函数或概率密度
- \(f(x)\)近似等于连续型随机变量\(X\)在点x处附近的无限小区段内,单位长度所占有的概率,反映了连续型随机变量X在点x处附近的概率“密集程度”
-
概率论重点 性质
- \(f(x)\ge 0,x\in(-\infty,+\infty)\)
- \(\int^{+\infty}_{-\infty}f(x)dx=1\)
- 如果满足以上两个性质,则\(f(x)\)必为某连续型随机变量X的密度函数
- 改变概率密度函数\(f(x)\)在个别点的函数值不影响\(F(x)\)的取值,故对固定的分布函数,概率密度函数不是唯一的
- 定理:设连续型r.v.X的分布函数(CDF)为\(F(x)\),概率密度分布函数(PDF)为\(f(X)\)则
- \(F(x)\)为连续函数(绝对连续函数)
- 若\(x\)时\(f(x)\)的连续点,则\(\frac{dF(x)}{dx}=f(x)\)
- 密度函数的确定方式
- 在\(F(x)\)的可导点\(x\)处,取\(f(x)=F^\prime(x)\)
- 在\(F(x)\)的不可导点\(x\)处,取\(f(x)\)为任意非负值
- 密度函数的确定方式
- 对于任意实数\(c\),则\(P\{X=c\}=0\)
- 在有限个点处改变\(f(x)\)的取值,不影响\(X\)的整体分布,则\(f(x)\)的表达式可以不唯一
- \(P\{a<X<b\}=P\{a\le X< b\}=P\{a<X\le b\}=P\{a\le X \le b\}=\int^{b}_{a}f(x)dx\)



#概率论重点 几种常见的连续型随机变量的概率分布
- 均匀分布
- 记作:\(X\sim U[a,b]\)
- \(f(x)=\begin{cases}\frac{1}{b-a},a\le x\le b \\ 0, 其他\end{cases}\)
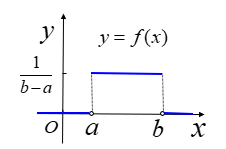
- \(F(x)=\begin{cases}0,x<a\\ \frac{x-a}{b-a},a\le x<b\\ 1, b\le x\end{cases}\)
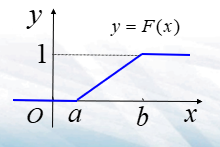
- \(P\{X\in I\}=P\{X\in I\cap[a,b]\}=\frac{I\cap [a,b]的长度}{b - a}\)
- 指数分布
- 记作:\(X\sim E(\lambda)\)
- \(f(x)=\begin{cases}\lambda e^{-\lambda x}, x\ge 0\\ 0, x < 0\end{cases}\)

- \(F(x)=\begin{cases}1-e^{-\lambda x},x\ge 0\\0,x<0\end{cases}\)

- 指数分布的无记忆性:\(P\{X>s+t|X>s\}=P\{X>t\}\)
- 证明:
- 证明:
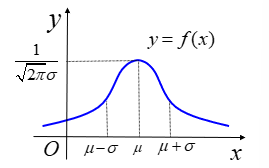
- 正态分布
- 标准正态分布表
- 记作:\(X\sim N(\mu,\sigma^2)\)
- \(f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\)
- \(F(x)=\frac{1}{\sqrt{2\pi}\sigma}\int^{x}_{-\infty}e^{-\frac{(t-\mu)^2}{2\sigma^2}}dt,-\infty<x<+\infty\)
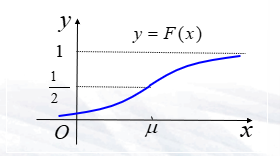
- \(\mu,\sigma^2\)的变化对密度函数图像的影响
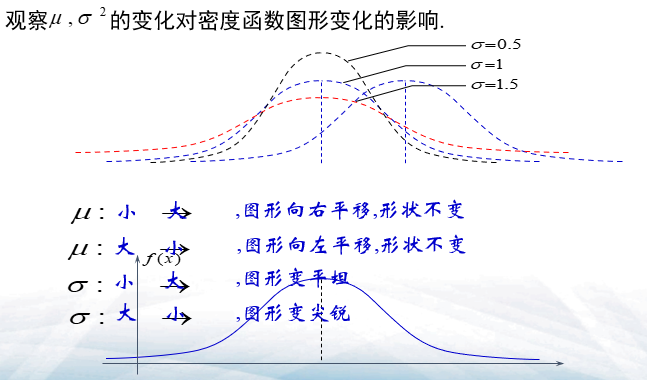
- 标准正态分布:
- \(\phi(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\)
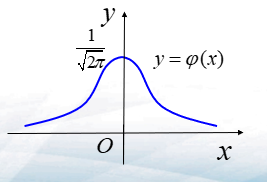
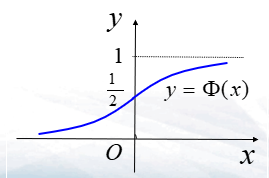
- \(\Phi(x)=\frac{1}{\sqrt{2\pi}}\int^{x}_{-\infty}e^{-\frac{t^2}{2}}dt,-\infty<x<+\infty\)

- \(\phi(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\)
- \(P\{X\le b\}=\Phi(\frac{b-\mu}{\sigma})\),\(P\{X>a\}=1-\Phi(\frac{a-\mu}{\sigma})\)

一维随机变量函数的分布
本节介绍当随机变量\(X\)的概率分布以及函数\(g(x)\)均已知时,如何求出\(Y=g(X)\)的概率分布 - 所谓求\(Y=g(X)\)的概率分布是指 - 若\(Y\)是离散型,则求\(Y\)的分布律 - 若\(Y\)是连续型,则求\(Y\)的密度函数 - 若\(Y\)既不是连续型也不是离散型,则求\(Y\)的分布函数 - 首先需要判断\(Y=g(X)\)的类型
离散型随机变量\(X\)的函数\(Y=g(X)\)的概率分布
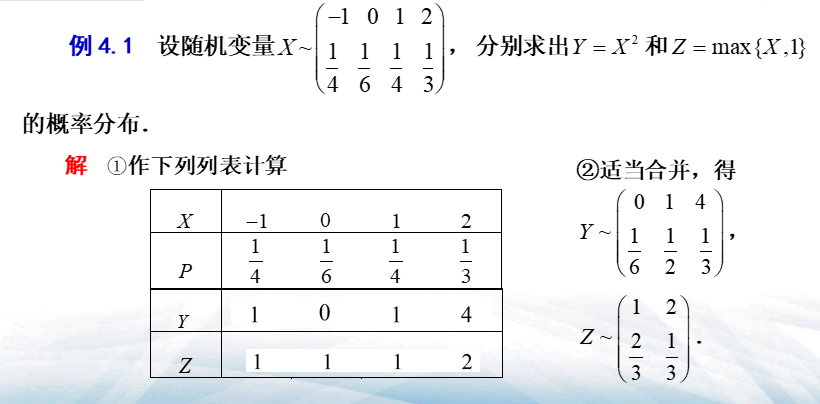
离散型随机变量X的分布律为:\(\(\begin{array}{c|cccc}X&x_1&x_2&...&x_i&...\\\hline P&p_1&p_2&...&p_i&...\end{array}\)\)
- 求\(Y\)的分布律的步骤为:
1. 在\(X\)的分布律中添加一行\(Y=g(X)\),并将\(y_i=g(x_i)(i=1,2,...)\)的值对应填入行中
2. 对其中\(Y\)取值相同的想适当进行概率合并,即得\(Y\)的分布律
#概率论重点 连续型随机变量\(X\)的函数\(Y=g(X)\)的概率分布
- 步骤
- 从分布函数着手:\(F_Y(y)=P\{T\le y\}=P\{g(X)\le y\}\)
- 对分布函数求导,得到概率密度函数
- 定理:
- 设随机变量\(X\)的密度函数为\(f_X(x)\cdot y=g(x)\)为\((-\infty,+\infty)\)内的单调函数,其反函数\(x=h(y)\)具有异界连续倒数,则\(Y=g(X)\)为连续型随机变量,其密度函数为:\(\(f_Y(y)=\begin{cases}f(h(y))|h^\prime(y)|, y在Y的取值范围内\\0,其他\end{cases}\)\)
- \(aX+b\sim N(a\mu+b, a^2\sigma^2)\)
- 如果\(a=\frac{1}{\sigma},b=-\frac{\mu}{\sigma}\)
- 如果连续性随机变量\(X\)的密度函数\(f_X(x)\)在有限区间\([a,b]\)之外取值为0,\(y=g(x)\)为\([a,b]\)上的单调函数,其反函数\(x=h(y)\)具有异界连续导数,则\(Y=g(x)\)为连续型随机变量,其密度函数为:(\(f_Y(y)=\begin{cases}f_X(h(y))|h^\prime(y)|,
\alpha\le y\le \beta\\0,其他\end{cases}\)\)其中\(\alpha=min\{g(a),g(b)\},\beta=max\{g(a),g(b)\}\)
