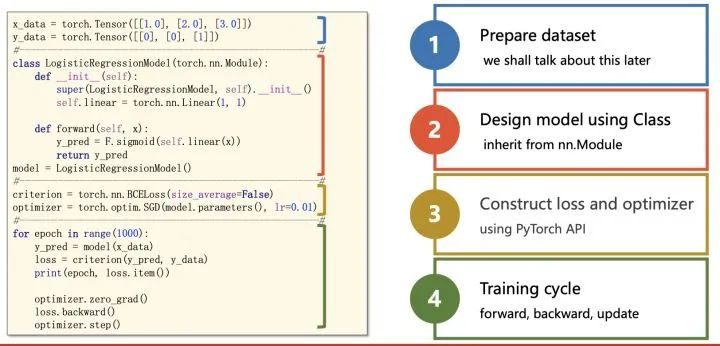
Pytorch编写深度学习模型的基本思路
- 模型学习过程
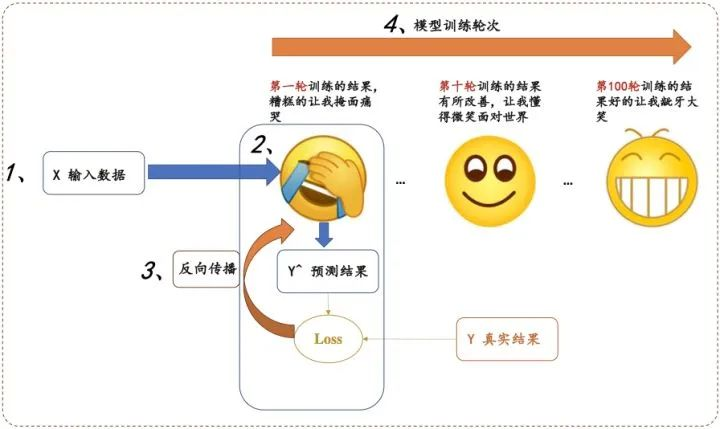
四大步骤
输入处理模块
torch.utils.data.Dataset
- 需要重写的方法
__init__(self)__getitem__(self, index)__len__(self)
torch.utils.data.Dataloader
- 构造方法:
Dataloader(dataset, batch_size = 1, shuffle = False)
模型构建模块
- 所有的模型需要继承
torch.nn.Module
- 需要实现的方法:
__init__(self)__forward__(self, x):向前传播的过程,在实现模型时,无需考虑反向传播
定义代价函数和优化器模块
criterion = nn.MSELoss(reduction = 'mean')
optimizer = torch.optim.SGD(model.parameters(), lr = 0.001, momentum=0.9)
构建训练过程
- 循环大致如下
def train(epoch): #
for i, data in enumerate(dataLoader, 0):
x, y = data
y_pred = model(x) # 前向传播
loss = criterion(y_pred, y) # 计算代价函数
optimizer.zero_grad() # 梯度清零,进行下一步计算
loss.backward() # 反向传播
optimizer.step() # 更新训练参数