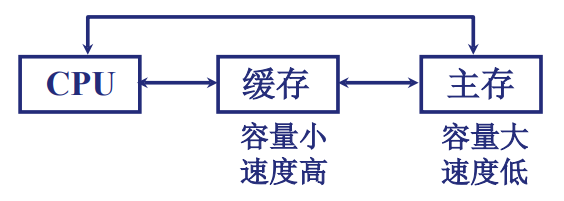
高速缓冲存储器
什么是Cache
Cache的提出: 在多体并行系统中,IO访存级别高于CPU访存级别,CPU需要等待,IO完成访存操作 而主存的速度发展低于CPU速度发展,CPU与DRAM速度每年增加50% 为了避免CPU空等的现象,提出了缓存的概念
-
Cache的理论依据:程序访问的[[局部性]]
-
Cache
- Cache是一种小容量高速缓冲存储器,由SRAM组成
- 由于Cache直接封装在CPU内部,速度几乎与CPU一样快
- 程序运行时,CPU使用的一部分数据/指令会预先成批的拷贝在Cache中
- 因此,可以说Cache中的内容是主存中部分内容的映像
- 当CPU需要从内存中读写数据或指令时,会先对Cache进行检查
- 命中:如果Cache中有想要的数据或指令,则直接从Cache中读取
- 未命中:如果Cache中没有想要的数据或指令,则先将数据或指令从内存中拷贝至Cache中,在进行读取
[!存储器层次的中心思想] 对于每个k,位于k层的更快更小的存储设备作为位于k+1层的更大更慢的存储设备的缓存。 换句话说,层次结构中的每一层都缓存来自较低一层的数据对象。
Cache的工作原理
主存与缓存的编址方式
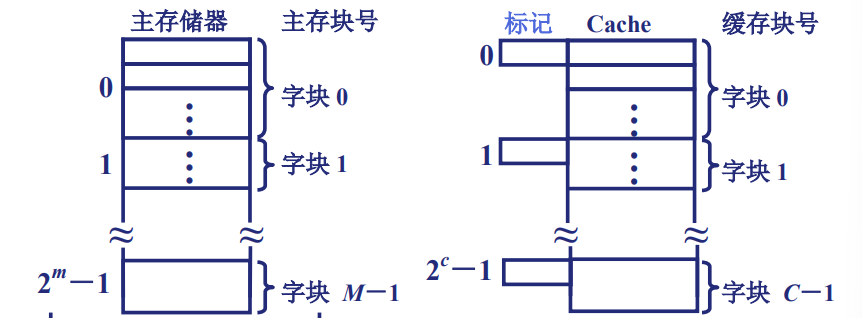 - 主存与缓存的地址组成:
- 主存地址组成:
- 主存与缓存的地址组成:
- 主存地址组成: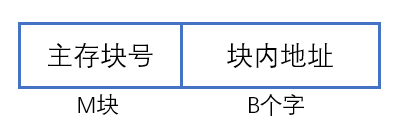 - 缓存地址组成:
- 缓存地址组成: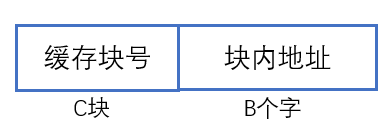 - 可得:
- 主存与缓存的块的大小相同,块内地址可以共用
- 因此为了统一二者的地址,我们需要在m与c之间做映射
- 可得:
- 主存与缓存的块的大小相同,块内地址可以共用
- 因此为了统一二者的地址,我们需要在m与c之间做映射
由于造价的限制,C的数量一定是远小于M的,因此如何做多对少的映射,需要特别处理
命中与不命中
- 命中:当需要k+1层中的数据时,该数据刚好缓存在第k层中,则称为命中
- 不命中:当需要k+1层中的数据时,该数据不在第k层中,则称为命中
不命中的几种情况: 1. 强制性不命中 1. 冷缓存:缓存为空,接下来则需要不断暖身(放置缓存),来提高命中率 2. 冲突不命中: - 在这种情况中,缓存足够大,但是因为对象会被映射到同一个缓存块中,会导致缓存一直不命中 3. 容量不命中: - 缓存太小,不能处理这个工作集
- 命中率的计算:(\(h=\frac{N_c}{N_c + N_m}\)\)
- \(N_c\):命中的次数
- \(N_m\):未命中的次数
- Cache的工作效率:$$e=\frac{\text{访问Cache的时间}}{\text{平均访问时间}}\times 100\% $$
- 命中率一般与Cache的容量和块长有关
Cache的基本结构
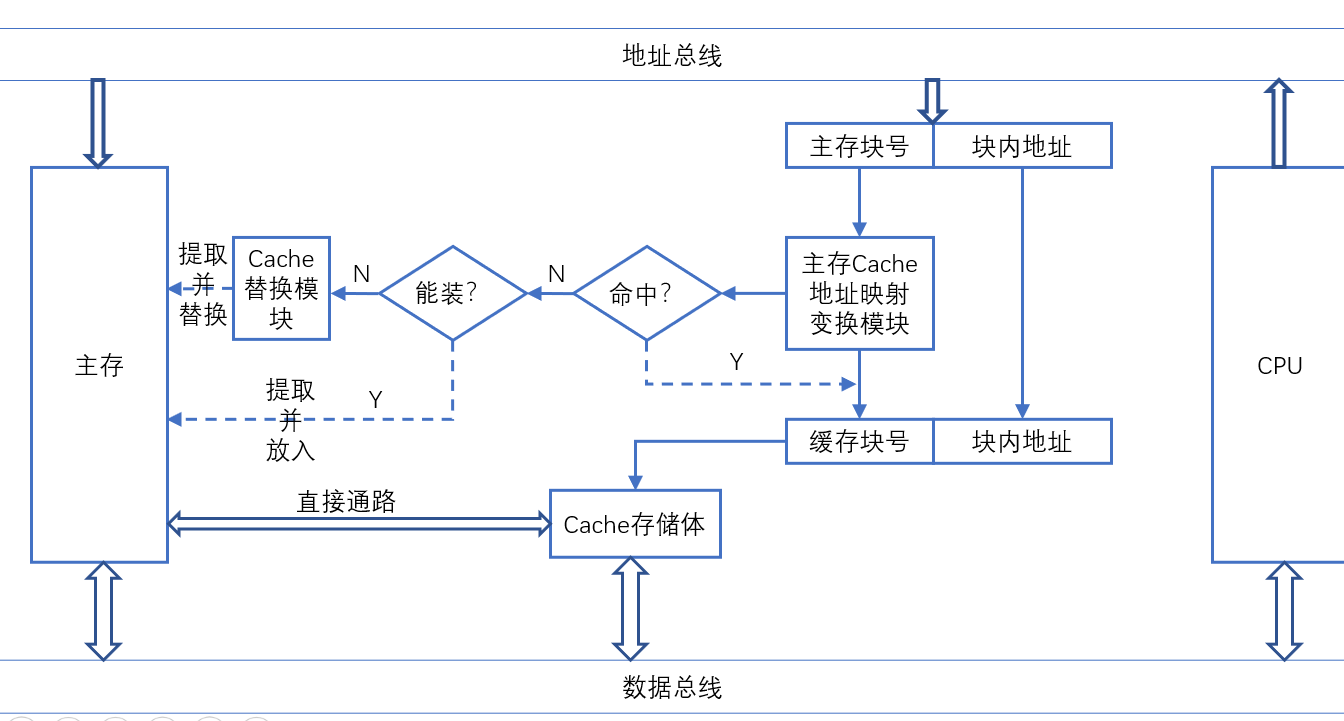 - 地址变换映射模块:将CPU送来的主存地址转换为Cache地址
- 主要是块号之间的转换
- 替换模块:由替换模块按一定的提货算法来确定从Cache内移出那个块返回主存,而存储新的主存块
- 地址变换映射模块:将CPU送来的主存地址转换为Cache地址
- 主要是块号之间的转换
- 替换模块:由替换模块按一定的提货算法来确定从Cache内移出那个块返回主存,而存储新的主存块
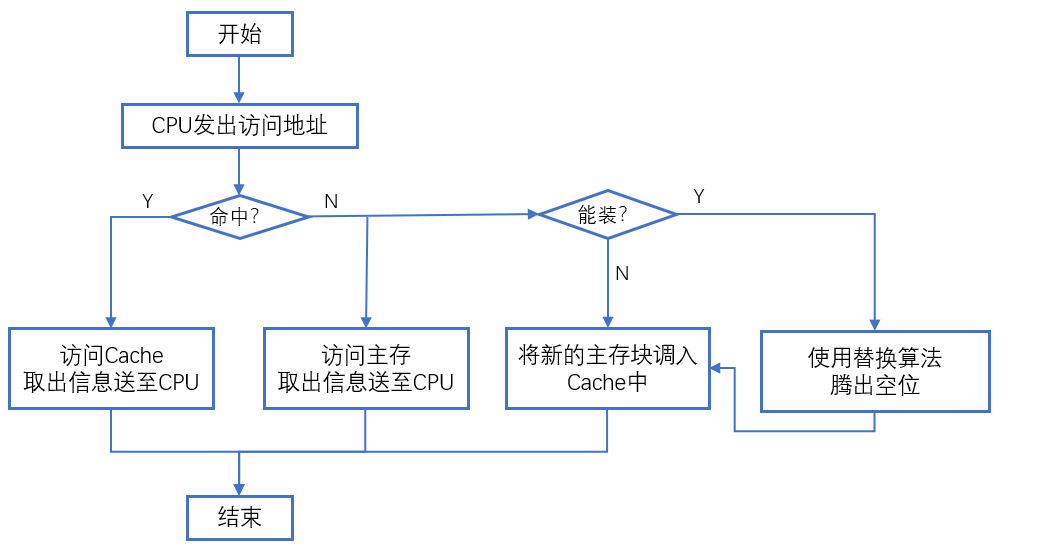
Cache的读写操作
- 流程图
Cache的改进
- 增加缓存级数
- 统一缓存和分立缓存
- 指令与数据分开存放
#计组重点 Cache——主存地址映射
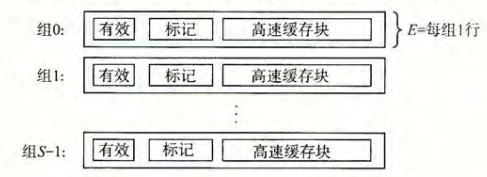
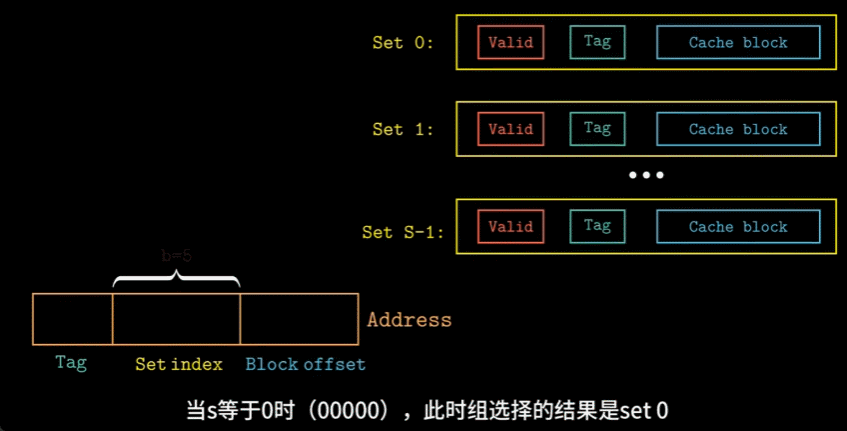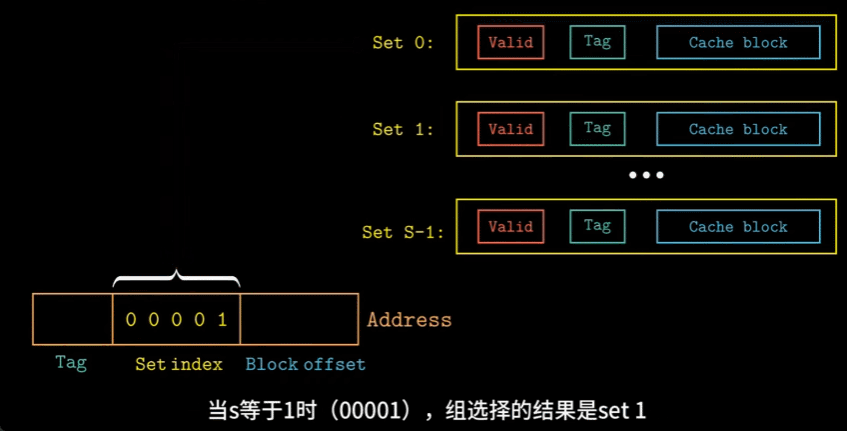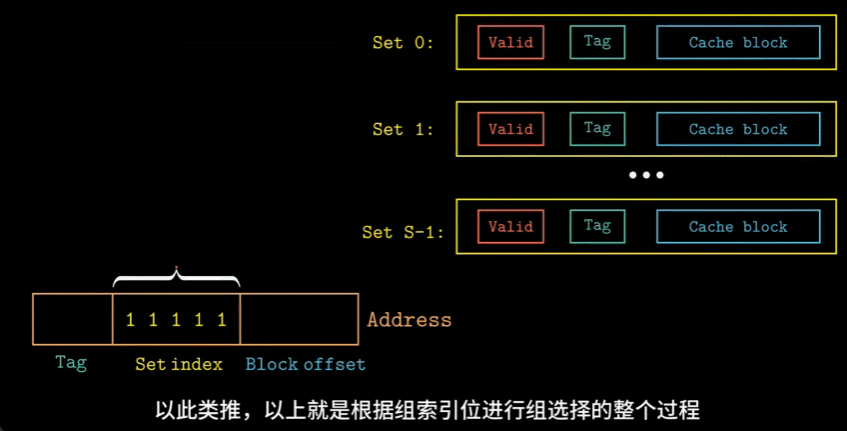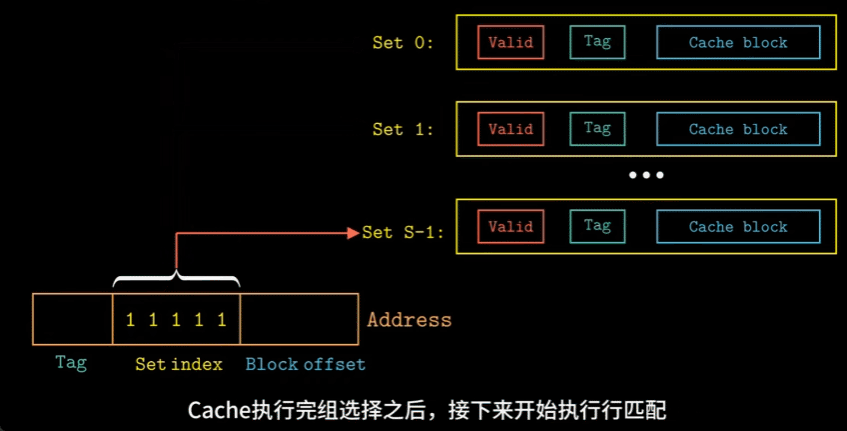
- 对于一个计算机系统,存储器的地址有\(m\)位,则构成了\(M=2^m\)个不同的地址,其高速缓存的组成为:
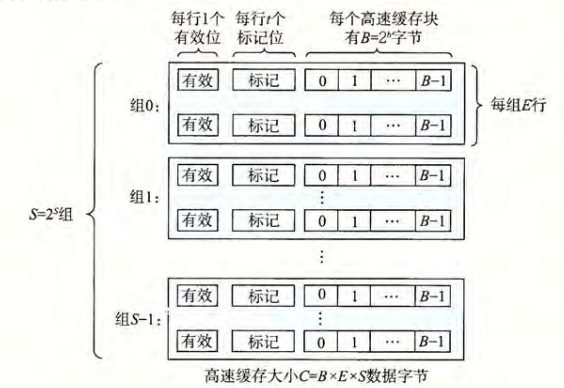
- \(S=2^s\)个高速缓存组
- 每个组包含\(E\)个高速缓存行
- 每个行包括\(B=2^b\)字节的数据块
- 一个有效位
- \(t=m-(b+s)\)个标记位
- 每个组包含\(E\)个高速缓存行
- \(S=2^s\)个高速缓存组
-
每一个地址中的标记与索引共同唯一的标识一个高速缓存中的块
一般而言,高速缓存的结构可以用元组\((S,E,B,m)\)来表示 高速缓存的大小(所有块的大小的和,不包括标记位和有效位)\(C=S\times E\times B\)
-
由于\(S\)与\(B\)的存在,一个地址可以被分为三个部分:
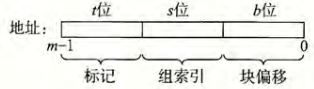
- 组索引:告诉我们这个字在哪个组中
- 标记:帮助我们在组中找到对应的块
- 块偏移:帮助我们在块中找到对应的字
直接映射高速缓存
- 每个组只有一行(\(E=1\))的高速缓存被称为直接映射高速缓存
-
字请求的过程:
- 组选择:根据地址中的组索引位来确定目标字会存储在哪一个组中
-
行匹配

- 当且仅当设置了有效位,而且高速缓存行中的标记与目标的地址中的标记相匹配时,则可以认为,这一行中包含了目标的副本
在只有一行的直接映射高速缓存中,匹配的方式非常简单,只需要判断数据是否有效(有效位是否为1),且标记是否匹配,则可以确定数据是否在缓存块中了
- 当且仅当设置了有效位,而且高速缓存行中的标记与目标的地址中的标记相匹配时,则可以认为,这一行中包含了目标的副本
-
字抽取:确定所需要的字在块中是从哪里开始的
- 块偏移提供了所需要的字的第一个字节的偏移
- 如果吧高速缓存看做一个行的数组一样,则可以把块看做是一个字节的数组,而字节偏移是到数组的一个索引
- 直接映射高速缓存中的不命中情况,只需要用新取出的行替换当前的行即可
- 组选择:根据地址中的组索引位来确定目标字会存储在哪一个组中
-
如果有一个直接映射高速缓存为\((S,E,B,m)=(4,1,2,4)\),则映射空间为:
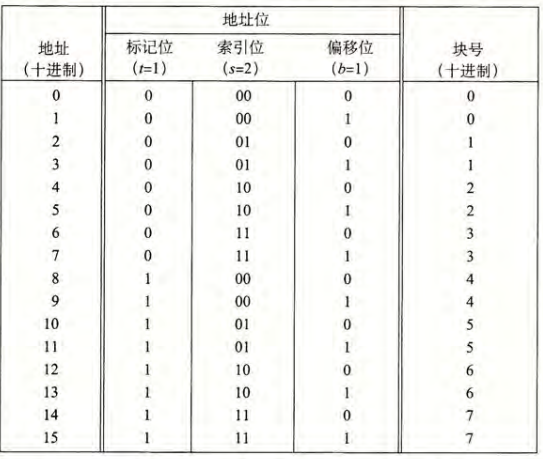
- 标记位和索引位共同标识了内存中的每一个块
- 由于有8个内存块,4个高速缓存组,则会有多个块会映射到同一个高速缓存组中
- 映射到同一个高速缓存组的块由标记位唯一标识
一个具体的对内存的读取过程,可以见CSAPP P340
-
直接映射的冲突不命中:
- 考虑一个函数为:
- 对函数的初步观察:函数具有良好的空间局部性,但是真的如此嘛???
- 做出映射表:
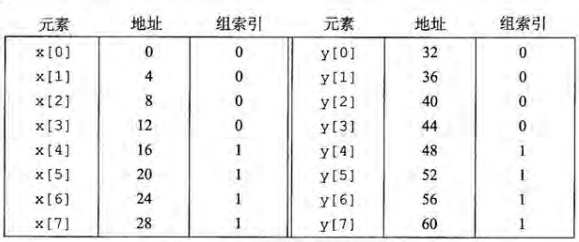
- 由这张图,可以看到,
x[0 ~ 4]与y[0~4]映射在了同一个组上,而在直接映射中,每一个组只有一行,这会导致每一个取数据,都是不命中的情况,导致程序运行效率降低,这种情况称为抖动[!note] 为什么使用中间的为作为索引? 如果使用高位做索引,那么一些连续的内存块就会映射到相同的高速缓存块。
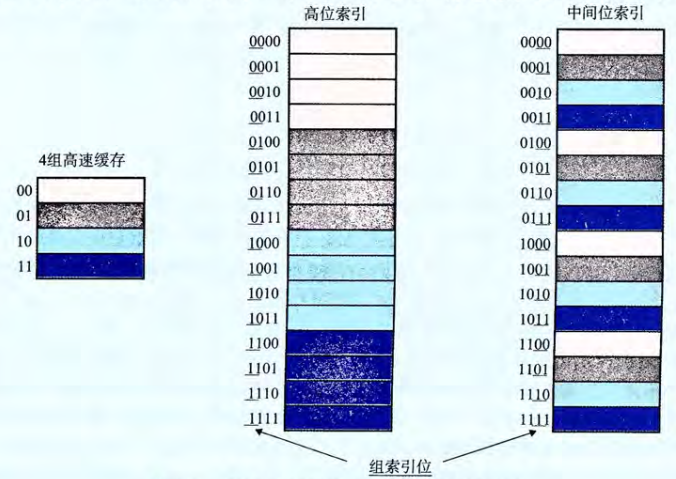 例如,对于一个4组高速缓存来说,会出现上图中的情况,如果一个程序拥有良好的空间局部性,顺序扫描一个数组的元素,那么在任何时刻,高速缓存都只保存着一个块大小的数组内容。
相比而言,使用中间位作为索引,相邻的块总是能映射到不同的高速缓存行中,在上图的情况中,高速缓存能够存放整个大小为C(高速缓存的大小)的数组片
例如,对于一个4组高速缓存来说,会出现上图中的情况,如果一个程序拥有良好的空间局部性,顺序扫描一个数组的元素,那么在任何时刻,高速缓存都只保存着一个块大小的数组内容。
相比而言,使用中间位作为索引,相邻的块总是能映射到不同的高速缓存行中,在上图的情况中,高速缓存能够存放整个大小为C(高速缓存的大小)的数组片
- 由这张图,可以看到,
组相联高速缓存
直接映射高速缓存中冲突不命中造成的问题源于每个组只有一行。 在组相联高速缓存中,放松了这条限制,每个组都保存多于一个的高速缓存行 - 组相联高速缓存:\(1<E<C/B\)
- 字节请求过程: 1. 组选择:与直接选择一致 2. 行匹配: - 检查多个行的标记和有效位,以确定锁清秋的字是否在集合中 - 相联存储器: - 一个(key, value)数组 3. 字选择 - 不命中时的行替换策略: - 最不常使用(LFU) - 最近最少使用(LRU) - 随机
全相联高速缓存
- 一个组包含所有的行:\(E=C/B\)
- 字请求的过程:
- 组选择:只有一组,无须选择
- 行匹配:与组相联高速缓存一致
- 字选择:与组相联高速缓存一致
相关题目
![[Cache例题]]
有关写的问题
相比读的情况,写的情况要相对复杂。假设我们要写一个已经缓存了的字\(w\)。在高速缓存更新了它的\(w\)副本后,怎么更新\(w\)在层次结构中紧接着的低一层中的副本?
- 命中:
- 直写:立即将\(w\)的高速缓存块写回低一层中
- 缺点:每次写都会引起总线流量
- 写回:尽可能的推迟更新,只有当替换算法要驱逐这个更新过的块时,才将其写入低一层中。
- 优点:根据局部性原理,写回能够显著的减少总线流量
- 缺点:增加了复杂性
- 在这种情况下,高速缓存必须为每个高速缓存行维护一个额外的修改位(dirty bit),用来表示数据是否被修改过
- 直写:立即将\(w\)的高速缓存块写回低一层中
- 不命中:
- 写分配:加载相应的低一层中的块到高速缓存中,然后更新这个高速缓存块
- 这种方法利用的是写的空间局部性
- 缺点:每一次不命中都会导致一个块从低一层传送到高速缓存
- 非写分配:避开高速缓存,直接将字写入低一层中
- 写分配:加载相应的低一层中的块到高速缓存中,然后更新这个高速缓存块