基于属性文法的处理方法
\(\(输入串\rightarrow语法树\rightarrow依赖图\rightarrow语义规则计算次序\)\) - 语法制导翻译法:有源程序的语法结构所驱动的处理方法 - 语义规则的计算: - 产生代码 - 在符号表中存放的信息 - 给出错误动作 - 执行其他任何动作 - 对于输入符号串的翻译也就是根据语义规则进行计算的结果 - 处理方法 - [[基于属性文法的处理方法#依赖图|依赖图]] - [[基于属性文法的处理方法#树遍历|树遍历]] - [[基于属性文法的处理方法#一遍扫描|一遍扫描]]
依赖图
- 使用依赖图(有向图)来描述一棵语法树中的结点的及程序上行和综合属性之间的互相依赖关系
- 依赖图中
- 为每一个属性设置一个结点
- 如果属性\(b\)依赖于属性\(c\),则从属性\(c\)的结点有一条有向边连接到属性\(b\)的结点
[!note] 依赖图示例
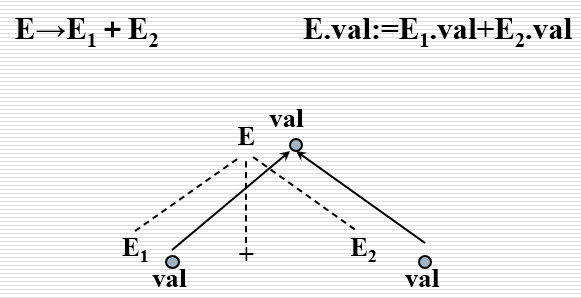
- 如果一个属性文法不存在属性之间的循环依赖,则称该文法为良定义的
[!info] 属性的计算次序 - 一个依赖图的任何拓扑排序都给出一个语法树中结点的语义规则计算的有效顺序 - 属性文法说明的翻译师精确的 - 基础文法用于建立输入符号串的语法分析树 - 根据语义规则建立依赖图 - 从依赖图的拓扑排序中,我们可以得到计算语义规则的顺序
树遍历
- 通过树遍历的方法计算属性的值
- 假设语法树已经建立,并且树中已有开始符号的继承属性和终结符的综合属性
- 以深度优先、从左到右的方式,对语法树进行遍历,知道计算出所有属性
一遍扫描
- 一遍扫描:在语法分析的同时计算属性值
- [[L-属性文法和自顶向下翻译#^d57566|L-属性文法]]适合一遍扫描的自上而下分析
- [[属性文法#^4e6ede|S-属性文法]]适合一遍扫描的自下而上分析
[!note] 语法制导翻译 所谓的语法制导翻译法,直观上说就是为文法中每个产生式配上一组语义规则,并且在语法分析的同时执行这些语义规则
- 语义规则被计算的时机:
- 自上而下:当一个产生式匹配输入串成功时
- 自下而上:当一个产生式被用于进行归约时
抽象语法树
- 抽象语法树:在语法树中去掉对翻译不必要的信息,从而获得更有效的源程序中间表示,即为抽象语法树
- 抽象语法树的建立:
mknode(op, left, right):建立一个运算符号结点op标号left和right分别指向左子树和右子树
mkleaf(id, entry):建立一个标识符结点id标号entry指向标识符在符号表中的entry
mkleaf(num, val)num标号val用于存放数的值