L-属性文法和自顶向下翻译
[!note] L-属性文法 如果对于每个产生式\(A\rightarrow X_1X_2\cdots X_n\),其每个语义规则中的每个属性/综合属性/\(X_j(1\le j \le n)\)的一个继承属性且这个继承属性仅依赖于: 1. 产生式\(X_j\)的左边符号的\(X_1, X_2, \cdots, X_{j-1}\)的属性(左兄弟结点的属性) 2. \(A\)的继承属性(父节点的继承属性) S-属性文法一定是L-属性文法 ^d57566
翻译模式
- 在翻译模式中,给出了使用语义规则进行计算的次序,这样可以将某些细节展现出来
[!note] 在翻译模式中,与文法符号相关的属性和语义规则,使用花括号\(\{\}\)括起来,插入到产生式右部的合适位置上:
R -> addop T {print(addop.lexme)} R
[!example] 将含有+和-运算的中缀表达式翻译为后缀形式 $$\begin{array} \ E\rightarrow T \quad R \ R \rightarrow addop \quad T{ print(addop.lexme)}R|\varepsilon \ T \rightarrow num{print(num.lexme)} \end{array} $$
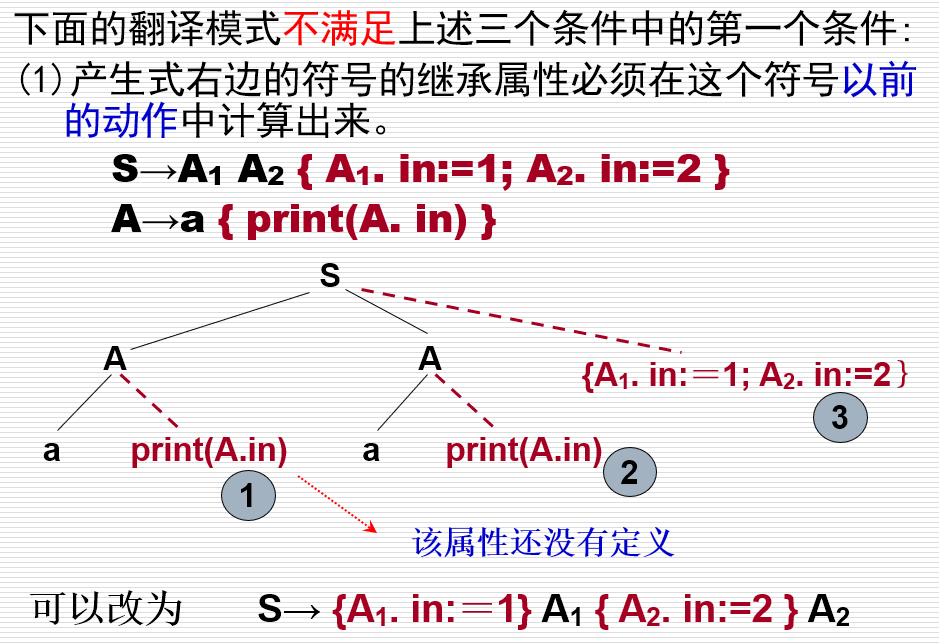
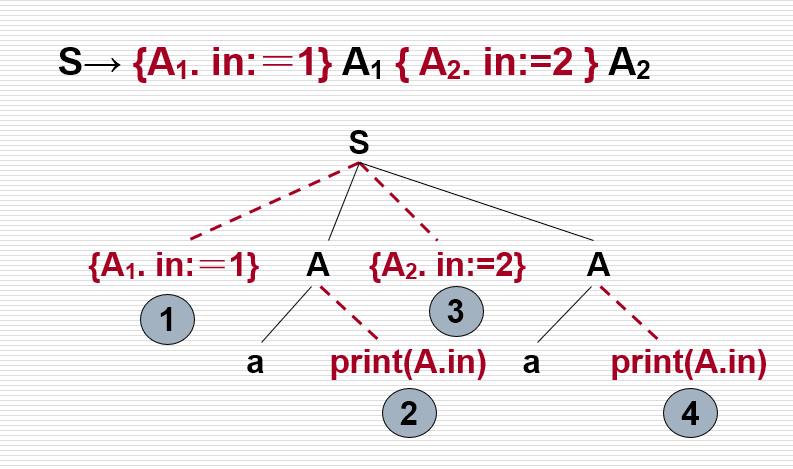
- 设计翻译模式的原则: - 设计翻译模式时,必须保证当某个动作引用一个属性时,它必须是有定义的。 - L-属性文法本身就能确保每个动作不会引用尚未计算出来的属性
翻译模式的建立
- 当只需要综合属性时:
- 为每一个语义规则建立一个包含赋值的动作,并且把这个动作放在相应的产生式右部的末尾

- 为每一个语义规则建立一个包含赋值的动作,并且把这个动作放在相应的产生式右部的末尾
- 如果既有综合属性又有继承属性,需要保证
- 产生式右边的符号的继承属性必须在这个符号以前的动作中计算出来
- 一个动作不能引用这个动作右边的符号的综合属性
- 产生式左边非终结符的综合属性只有在它所引用的所有属性都计算出来以后才能计算。(计算这种属性的动作通常可以放在产生式右端的末尾处)
自顶向下翻译
- 动作是在处于相同位置上的符号被成功匹配时执行的
- 为了构造不带回溯的自顶向下语法分析,必须消除文法中的左递归
- 当消除一个翻译模式的基本文法的左递归时,同时考虑属性——适合带综合属性的翻译模式