- [[#介绍|介绍]]
- [[#介绍#一个简单的例子|一个简单的例子]]
- [[#介绍#页表存在哪里|页表存在哪里]]
- [[#介绍#列表中究竟有什么|列表中究竟有什么]]
- [[#介绍#分页: 也很慢|分页: 也很慢]]
- [[#快速地址转换(TLB)|快速地址转换(TLB)]]
- [[#快速地址转换(TLB)#TLB的基本算法|TLB的基本算法]]
- [[#快速地址转换(TLB)#示例: 访问数组|示例: 访问数组]]
- [[#快速地址转换(TLB)#由谁来处理TLB未命中|由谁来处理TLB未命中]]
- [[#较小的表|较小的表]]
- [[#较小的表#简单的解决方案: 更大的页|简单的解决方案: 更大的页]]
- [[#较小的表#混合方法: 分页和分段|混合方法: 分页和分段]]
- [[#较小的表#多级页表|多级页表]]
- [[#较小的表#详细的多级示例|详细的多级示例]]
分页
介绍
- 操作系统用来解决大多数空间管理问题的方法:
- 将空间分割成不同长度的分片
- 问题: 将空间切成不同长度的分片后, 空间本身会变得碎片化, 随着时间推移, 分配内存会变得困难
- 将空间分割为固定长度的分片 -> 分页
- 将空间分割成不同长度的分片
一个简单的例子
- 一个只有 64 字节的小地址空间,有 4 个 16 字节的页(虚拟页 0、1、2、3)
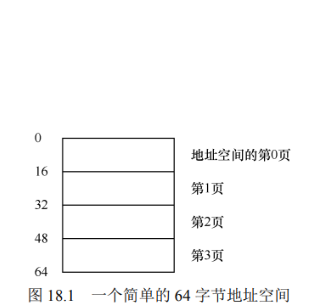
- 物理内存

- 由一组固定大小的槽块组成
- 由上图可以看出, 虚拟地址空间的页放在物理内存的不同位置, 并且, 操作系统还自己使用掉了一些物理内存
- 分页的优点:
- 灵活性: 通过完善的分页方法, 操作系统能够高效的提供地址空间的抽象, 无论进程是如何使用地址空间的
- 空闲空间管理的简单性: 如果操作系统希望将 64 字节的小地址空间放到 8 页的物理地址空间中,它只要找到 4 个空闲页
[!note] 简单性的例子 可能操作系统中保留了一个空闲列表, 在这个列表中保存了所有空闲页, 只需要从这个列表中拿出 4 个空闲页即可. 在上面的图片中, 就是找到了页帧 2, 3, 4, 6
- 页表: 记录地址空间的每个虚拟页放在物理内存中的位置
- 每个进程都有一个页表来保存以上信息
- 作用: 为地址空间的每个虚拟页保存地址转换
- 例子: 假如我们要访问一个地址
0x21, 首先变为二进制形式010101, 再根据位数的划分, 获得虚拟页号 (VPN)和偏移量, 由于一个页的大小是 16 字节, 因此, 页内偏移量应该需要有 4 位来表示, 则虚拟页号需要有 2 位来表示 (虚拟地址的长度为 6 位, 仅剩余 2 位用于表示虚拟页号, 也就是说, 可以有 4 个页). 接下来是地址转换的过程, 首先根据虚拟页号找到对应的页, 在加上偏移量, 我们就可以找到目标内容了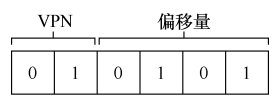
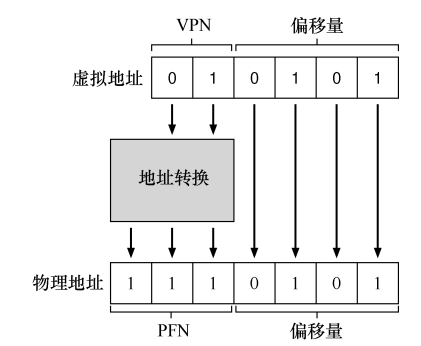
页表存在哪里
- 将每个进程的页表存储在内存中
- 但很多操作系统内存本身都可以虚拟化, 因此页表可以存储在操作系统的虚拟内存中
列表中究竟有什么
- 页表实际上就是一种数据结构, 用于将虚拟地址 (VPN, 虚拟页号)映射到物理地址 (物理帧号), 因此, 我们可以在其中任意添加自己需要的内容
- 简单的表现形式: 线性页表或者是链表等
- 每个 PTE 的内容
- 有效位 (valid bit), 用于指示特定地址转换是否有效
- 保护位 (protection bit), 表明页是否可以读取, 写入或执行
- 存在位 (present bit), 表示该页是在物理存储器还是在磁盘上
- .....
分页: 也很慢
- 为了找到想要的 PTE 的位置, 硬件需要执行的运算:
VPN = (VirtualAdderss & VPN_MASK) >> SHIFTPTEAddr = PageTableBaseRegister + (VPN * sizeof(PTE))
- 利用分页访问内存的完整过程
// Extract the VPN from the virtual address VPN = (VirtualAddress & VPN_MASK) >> SHIFT // Form the address of the page-table entry (PTE) PTEAddr = PTBR + (VPN * sizeof(PTE)) // Fetch the PTE PTE = AccessMemory(PTEAddr) // Check if process can access the page if (PTE.Valid == False) RaiseException (SEGMENTATION_FAULT) else if (CanAccess(PTE.ProtectBits) == False) RaiseException(PROTECTION_FAULT) else // Access is OK: form physical address and fetch it offset = VirtualAddress & OFFSET_MASK PhysAddr = ((PTE.PFN << PFN_SHIFT) I offset Register = AccessMemory(PhysAddr) - 引出的两个问题和解决方法:
- 运行速度缓慢 -> 快速地址转换 (TLB), 这个方法使用到了缓存的概念
- 占用太多内存 -> 使用较小的表
快速地址转换 (TLB)
[!note] 为什么要引入 TLB 使用分页作为核心机制来实现虚拟内存, 可能会带来较高的性能开销. 因为要使用分页, 就需要将地址空间切分为大量固定大小的但也, 并且需要记录这些单元的地址映射信息. 由于这些映射信息一般存储在物理内存中, 所以在转换虚拟地址时候, 分页就需要额外访问一次内存. 这就导致了每次的指令获取, 显式加载或保存, 都需要额外读取一次内存以得到转换信息, 这样就回面临以下问题: 1. 如何才能加速虚拟地址转换, 尽量避免额外的内存访问? 2. 需要什么样的硬件支持? 3. 操作系统应该如何支持
为了让访存更快, 就不免得想起缓存的概念了, 可以回想, 缓存帮助我们加快了对内存的访问. 那么, 可否将相似的概念转移到页表上来, 毕竟都是访问内存, 本质上没有什么不一样, 这样就得到了所谓的地址转换旁路缓冲存储器 (translation-lookaside buffer, TLB). 对于每一次内存访问, 硬件先检查 TLB, 看看其中是否有期望的转换映射, 如果有, 就完成转换, 不用访问页表.
TLB 的基本算法
VPN = (VirtulAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True)
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | OFFSET
AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB Miss
PTEAddr = PTBR + (VPN * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtecBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInsruction()
示例: 访问数组
- 小地址空间中的一个数组:
 现在有一个简单的数组遍历程序:
当访问第一个数组元素
现在有一个简单的数组遍历程序:
当访问第一个数组元素 a[0]时, 假设这是程序第一次访问该数组, 结果是 TLB 未命中, 将VPN=06页面载入到 TLB 中, 后续访问a[1-2]时候, 就有缓存命中; 但是当程序访问a[3]时候, 又会导致一次 TLB 未命中, 因为VPN=07页面不在 TLB 中, 但是后续对a[4-6]的访问都会命中 TLB, 同样的, 访问a[7-9]也会产生相同的情况. 总结, 这 10 此数组访问操作中 TLB 的行为表现: miss, hit, hit, miss, hit, hit, hit, miss, hit, hit[!note] TLB 的性能 如果在这次循环后不久, 该程序再次访问该数组, 我们会看到更好的结果, 如果 TLB 足够大, 就能够缓存上面所需要的缓存映射, 就会产生全部命中的效果. 由于时间局部性, TLB 的命中率会很高. 类似其他缓存, TLB 的成功依赖于空间和时间局部性. 如果程序表现出这样的局部性, TLB 的命中率就会很高.
由谁来处理 TLB 未命中
- 硬件
- 发生未命中时候, 硬件会遍历页表, 找到正确的页表项, 取出想要的转换映射, 用它来更新 TLB, 并且重试这个指令.
- 发生 TLB 未命中时候, 硬件系统会抛出一个异常, 这会暂停当前的指令流, 将特权级提升至内核模式, 跳转至陷阱处理程序.
- 陷阱处理程序是操作系统的一段代码, 用于处理 TLB 未命中
较小的表
简单的解决方案: 更大的页
- 以 32 位地址空间为例, 但这次假设使用 16 KB 的页, 则可以将地址分为: 18 位 VPN 和 14 位偏移量, 这样更少的页, 就只需要更少的空间去存储这些页
- 问题: 大内存页会导致每页内的浪费 (页内碎片 internal fragmentation), 导致应用程序会分配页, 但是只是用其中的一笑部分, 这样内存中很快就回充满这些过大的页
[!caution] 为什么单级页表中的每一项都需要存在? 单级页表可以看成以虚拟地址的虚拟页号作为索引的数组, 整个数组的起始地址存储在页表基地址寄存器中. 翻译某个虚拟地址即根据其虚拟页号找到对应的数组项, 因此整个页表必须在物理内存中连续, 其中没有被用到的数组也需要预留着.
混合方法: 分页和分段
- 将分页和分段相结合, 以减少页表的内存开销
- 为什么有用?
- 假设中的情况: 我们有一个地址空间, 其中堆和栈的使用部分都很小, 映射情况如下:
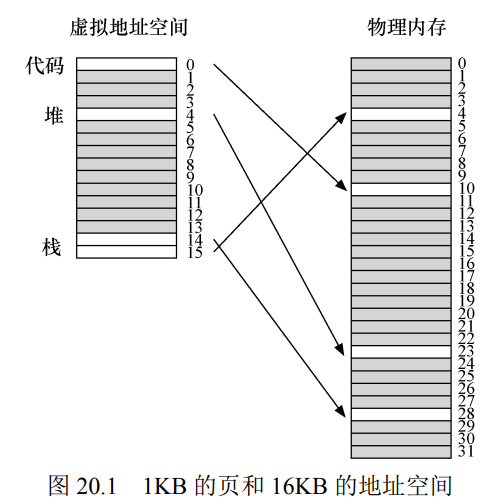
- 可以看到大部分的页表都没有使用, 充满了无效的项
- 假设中的情况: 我们有一个地址空间, 其中堆和栈的使用部分都很小, 映射情况如下:
- 段页方法: 不是为进程的整个地址空间提供单个页表, 而是为每个逻辑分段提供一个
- 在上面的例子中, 我们可以有 3 个页表, 地址空间的代码、对和栈部分各有一个
- 在分段中, 每个段还有基址寄存器和界限寄存器, 用来告诉我们段的大小, 则在 MMU 中依旧有这些相似的结构:
- 基址 -> 该段的页表的物理地址
- 界限 -> 指示页表的结尾 (即有多少有效位)
- 例子: 32 位虚拟地址空间包含 4 KB 页面, 并且地址空间分为 4 个段, 则虚拟地址如下所示:

- 提取的方法:
- 段页方法的关键区别在于, 每个分段都有界限寄存器, 每个界限七级村保存了段中最大有效页的值
- 如果代码段使用它的前 3 个页, 则代码段页表将只有 3 个项分配给它, 并且界限寄存器将被设置为 3
- 内存访问超出段的末尾将产生一个异常, 并且可能导致进程终止
- 问题: 这种方法依旧使用分段的概念, 分段并不灵活, 因为它假定地址空间有一定的使用模式. 例如, 如果有一个大而稀疏的对, 仍然可能导致大量的页表浪费. 其次, 这种杂合导致外部碎片再次出现. 尽管大部分内存是以页面大小单位管理额, 但页表现在可以是任意大小. 因此, 在内存中为他们寻找空闲空间则变得更为复杂.
多级页表
- 与段页方法相似的思路: 去掉页表中的所有无效的区域, 而不是将他们全部保留在内存中. 在多级页表中, 将线性页表变为了类似树的结构
- 多级页表的基本思想:
- 首先, 将页表分成页大小的单元
- 然后, 如果整页的页表项无效, 就完全不分配该页的页表
- 为了追踪页表的页是否有效, 使用了名为页目录的新结构
- 页目录可以告诉你页表的页在哪里, 或者页表的整个页不包含有效页
- 页目录的组成: 页目录项(PDE, Page Directory Entries), 包含了有效位(valid bit)和页帧号(page frame number , PFN)
[!note] 页目录中的有效位 在页目录中的有效位的含义稍有不同, 如果 PDE 项是有效的, 则意味着该项指向的页表中至少有一页是有效的, 即在该 PDE 所指向的页中, 至少一个 PTE, 其有效位被设置为 1. 如果 PDE 项无效, 则 PDE 的其余部分没有定义.
- 例子:
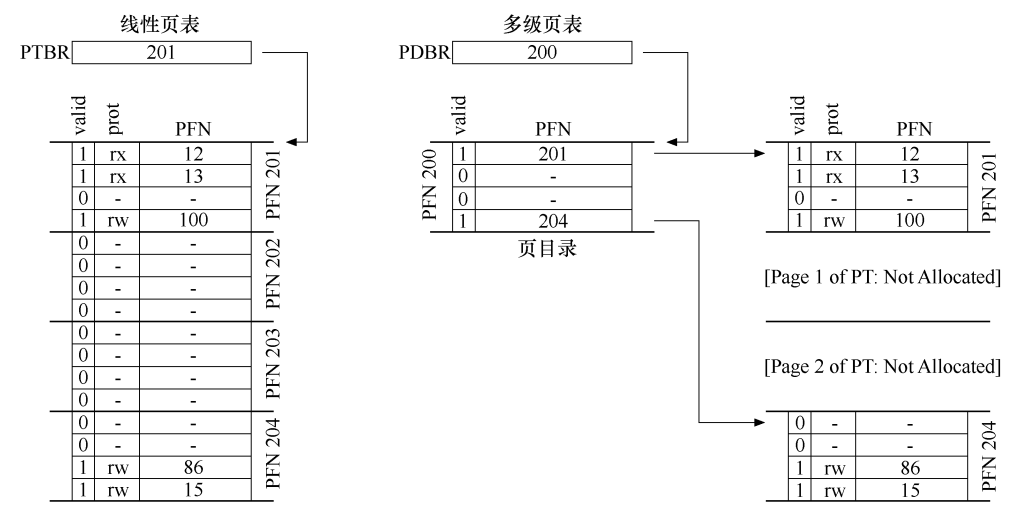
- 左侧的线性页表: 即使地址空间的大部分中间区域无效, 我们仍然需要为这些区域分配页表空间(页表的中间两页)
- 右侧的多级页表: 因为页目录仅将页表的两页标记为有效, 因此, 页表仅两页就驻留在内存中, 而其他未使用的页并未被分配
- 多级页表的工作方式: 只是让线性页表的一部分消失, 并使用页目录来记录页表的哪些页被分配
- 多级页表的优势:
- 多级页表分配的页表空间, 与正在使用的地址空间内存量成比例
- 通常较为紧凑, 并且支持稀疏的地址空间
- 如果仔细构建, 页表的每个部分都可以整齐的放入一页中, 从而更容易管理内存
- 操作系统可以在需要分配或增长页表时简单的获取下一个空闲页
[!note] 多级页表与线性页表相比 线性页表: 整个线性页表必须连续驻留在物理内存中. 对于一个大的页表, 找到如此大量的、未使用的连续空闲物理内存, 可能是一个相当大的挑战 多级页表: 多级页表中的页目录, 指向页表的各个部分. 这种间接的方法, 让我们能够将页表页放在物理内存的任何地方
- 操作系统可以在需要分配或增长页表时简单的获取下一个空闲页
- 多级页表的代价:
- 时间代价: 需要更多次的访存
- 在 TLB 未命中时候, 需要从内存加载两次, 才能从页表中获取正确的地址转换信息 (一次用于页目录, 另一次用于 PTE 本身), 而线性页表只需要一次加载
- 复杂性
- 时间代价: 需要更多次的访存
详细的多级示例
[!tip] 对复杂性表示怀疑 系统设计者应该谨慎对待让系统增加复杂性. 好的系统构建者所做的就是: 实现最小复杂性的系统, 来完成手上的任务. 例如, 如果磁盘空间非常大, 则不应该设计一个尽可能少使用字节的文件系统. 同样的, 如果处理器速度很快, 建议在操作系统中编写一个干净、易于理解的模块, 而不是 CPU 优化的、手写汇编的代码. 注意过早优化的代码或其他形式的不必要的复杂性. 这些方法会让系统难以理解、维护和调试 - 设想一个大小为 16 KB ( 14 位)的小地址空间, 其中包含了 64 个字节的页, 这样, 我们就获得了一个 14 位的虚拟地址空间, VPN 有 8 位, 偏移量有 6 位 - 假如这是一个线性页表, 即使只有一小部分地址空间正在使用, 线性页表也会有 \(2^8\) 个项 - #OS重点 为上述情况构建一个二级页表 - 首先从完整的现行页表开始, 将其分解成页大小的单元 - 这个完整的页表有 256 (8 位 VPN) 个项, 假设每个 PTE 的大小是 4 个字节, 因此, 我们一个页表的大小是 1 KB (\(256 \times 4\)), 而我们有 64 字节 (8 位偏移量) 的页, 则 1 KB 的页表 (原)可以拆分为 16 个 64 字节的页 (\(16\times 4\)), 每个页可以容 16 个 PTE
- 获取页目录的方法: \(PDEAddr = PageDirBase + (PDIndex \times sizeof(PDE))\) - 页目录项标记 - 无效: 访问无效, 引发异常 - 有效: 从页目录指向的页表的页中获取页表项 (PTE), 利用 VPN 中剩余位索引到页表的部分 - 获得 PTE 地址的方法:
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))- 现假设有一个页目录和页表如下, 并且要访问虚拟地址0x3F80:- Bin:
11 11|11 10|00 0000- 页目录索引为1111, 找到图中的最后一个页目录, 得到 PFN 为101, 有效位为 1 - 找到位于地址101处的页, 从 VPN 中获得剩余的位1110, 则找到了倒数第二个 PFN, 为 55 - 在根据偏移量, 获得最后的物理地址:0x37 << 6 | 0x00 = 0x0dc0
超过两级的页表
- 构建多级页表的目标: 使页表的每一部分都能放入一个页
- 如果页目录太大怎么办? -> 使用多级页表
- 要确定多级表中需要多少级别才能使页表的所有部分放入一页, 首先要确定多少页表项可以放入一页
 对于这个例子, 有 14 位留给了页目录, 如果我们的页目录有 \(2^{14}\) 个项, 那么它不是一个页, 而是 128 个页, 因此我们让多级页表的每一个部分放入一页的目标失败了
对于这个例子, 有 14 位留给了页目录, 如果我们的页目录有 \(2^{14}\) 个项, 那么它不是一个页, 而是 128 个页, 因此我们让多级页表的每一个部分放入一页的目标失败了- 因此, 我们为树再添加一层, 将页目录本身拆分成多个页, 然后在骑上添加另一个页目录, 指向页目录的页:

地址转换过程: 记住 TLB
以下是两级页表的地址转换的整个过程
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // Hit
if (CanAccess(TlbEntry.ProtecBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // Miss
PDIndex = (VPN & PD_MASK) >> PD_SHIFT
PDEAddr = PDBR + (PDIndex * sizeof(PDE))
PDE = AccessMemory(PDEAddr)
if (PDE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else
// PDE is valid: now fetch PTE from page table
PTIndex = (VPN & PT_MASK) >> PT_SHIFT
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectionBits)
RetryInstruction()
反向页表
在反向页表中, 我们保留了一个页表, 其中的项代表系统的每个物理页, 而不是有许多页表 页表项告诉我们那个进程正在使用此页, 以及该进程的那个虚拟页映射到此物理页 现在, 要找到正确的项, 就是要搜索这个数据结构
[!note] 反向页表的启示 反向页表说明了一件事: 页表只是数据结构. 你可以对数据结构做很多疯狂的事情, 让他们更小或更大, 抑或更快或更慢
将页表交换到磁盘
- 一些系统将页表放入内核虚拟内存, 从而允许系统在内存压力较大的时候, 将这些页表中的一部分交换 (swap) 到磁盘
超越物理内存: 机制
[!question] 更大的内存空间 到目前为止, 我们一直假定地址空间非常小, 能够放入物理内存. 事实上, 我们假设每个正在运行的进程的地址空间都能放入内存. 我们将放松这些大的假设, 并假设我们需要支持许多同时运行的巨大地址空间. 为了达到这个目的, 需要在内存层级上再加一层. 到目前为止, 我们一直假设所有页都驻留在物理内存中. 但是, 为了支持更大的地址空间, 操作系统需要把当前没有在使用的部分地址空间找个地方存储器来. 一般来说, 这个地方就是硬盘. 那么, 我们要如何利用硬盘, 来为程序制造一个巨大虚拟地址空间的假象? 有了这个巨大的地址空间, 就不必担心程序的数据结构是否有足够空间存储, 只需要自然地编写程序, 根据需要分配内存, 并且, 增加交换空间让操作系统为多个并发运行的进程都提供巨大的地址空间
交换空间
- 交换空间 (swap space): 在硬盘上的用于物理页的移入移出所使用的空间
- 这样的空间能够让操作系统以页大小为单元读取或者写入
- 为了达到这个目的, 操作系统需要记住给定页的硬盘地址
- 交换空间的大小决定了系统在某一时刻能够使用的最大内存页数
- 这样的空间能够让操作系统以页大小为单元读取或者写入
- 样例: 一个 4 页的物理内存和一个 8 页的交换空间
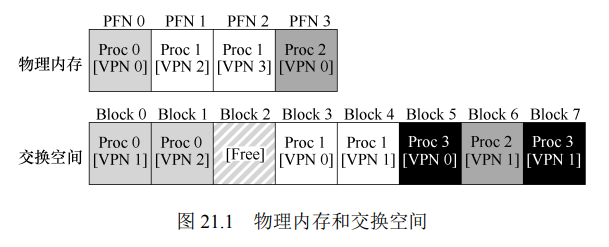
- 有 3 个进程正在共享物理内存, 但是 3 个中的每一个都只有一部分的有效页在物理内存中, 剩余的页面在硬盘的交换中
- 对于进程 3 来说, 所有的页都在交换空间中, 很显然, 进程 3 现在没有在运行
[!attention] 交换空间不是唯一的硬盘交换目的地 如, 假设运行一个二进制程序, 这个二进制程序的代码页最开始在硬盘上, 但是程序运行的时候需要被加载到内存中. 但, 如果系统需要在物理内存中腾出空间以满足其他需求, 则可以安全的重新使用这些代码页的内存空间, 因为稍后它由可以重新从硬盘上的二进制文件加载
存在位
在前面的 TLB 我们已经了解了在有 TLB 的情况下, 如何找到页, 接下来所讲述的就是在使用了交换空间的情况下, 如何使用 TLB 来查找一个页, 因为当硬件在 PTE 中查找时候, 可能发现页不在物理内存中 - 存在位: -
1: 在物理内存中 -0: 在硬盘的交换空间中 [!note] 页错误 访问不在物理内存中的页, 这种行为通常被称为页错误 (page fault) 当出现页错误的时候, 操作系统会执行页错误处理程序
页错误
[!note] 页错误程序的执行者 在 TLB 未命中的情况下, 我们有两种类型的系统: 1. 硬件管理的 TLB (硬件在页表中找到需要的转换映射) 2. 软件管理的 TLB (操作系统执行查找过程) 但不论在那种系统中, 如果页不存在, 都由操作系统负责处理页错误 - 页错误处理程序的执行内容: - 找到存储在交换空间中的页 - 硬盘 I/O 完成后, 操作系统更新页表, 将此页标记为存在 - 更新页表项 PTE 的 PFN 字段以记录新获取页的内存位置 - 重试触发页错误处理程序的指令 [!attention] TLB 可能依旧是未命中 注意, 在下一次重新访问 TLB 时候, 依旧会触发未命中 因为页错误处理程序仅仅是将页从硬盘的交换空间中提取到物理内存中, 还未更新 TLB 但由于这一次的页在内存中, 因此会将页表中的地址更新到 TLB 中 当然, 也可以在页错误处理程序中, 添加更新 TLB 的功能, 具体情况与操作系统的实现相关
[!question] 操作系统如何知道所需的页在哪? 在许多系统中, 页表示存储这些信息最自然的地方 因此, 操作系统可以用 PTE 中的某些位来存储硬盘地址, 这些为通常用来存储像页的 PFN 这样的数据. 当操作系统接收到页错误时候, 它会在 PTE 中查找地址, 并将请求发送到硬盘, 将页读取到内存中
[!attention] I/O 与阻塞 当 I/O 在运行时候, 进程将处于阻塞的状态. 因此, 当页错误正常处理时候, 操作系统可以自由地运行其他可执行的进程 这样的交叠是多道程序系统充分利用硬件的一种方式
内存满了怎么办
内存满时, 操作系统会交换出一个或多个页, 一遍为操作系统即将交换入的新页留出空间 具体的换出或替换策略, 被称为[[分页#超越物理内存 策略|页交换策略]]
页错误处理流程
PEN FindFreephysicalPage()
if (PFN ==-1) //no free page found
PFN EvictPage () //run replacement algorithm
DiskRead(PTE.DiskAddr,pfn) //sleep (waiting for I/O)
PTE.present = True //update page table with present
PTE.PFN = PFN //bit and translation (PFN)
RetryInstruction () //retry instruction
交换何时真正发生
- 执行释放: 当操作系统发现有少于 LW (低水位线, Low Watermark)个页可用时候, 后台负责释放内存的线程会开始运行, 直到有 HW (高水位线, High Watermark)个可用的物理页
[!note] 负责释放内存的线程 这样的后台线程有时称为交换守护进程或也守护进程 在他执行结束后, 会进入休眠状态
[!info] 性能 通过同时执行多个交换过程, 我们可以进行一些性能优化. 例如, 许多系统会把多个要写入的页聚集或分组, 同时写入到交换区间, 从而提高硬盘的效率. 这种操作减少了硬盘的寻道和旋转开销, 显著提高了性能
[!note] 预取机制 由于换页过程涉及耗时的磁盘操作, 因此操作系统往往会引入预取机制进行优化. 预取机制的想法: 当发生换入操作时候, 预测还有哪些页即将被访问, 提前将他们一并换入物理内存, 从而减少发生缺页异常的次数
[!note] 按需分配页 当应用程序申请分配内存时候, 操作系统可以选择将新分配的虚拟页标记位已分配但未映射值物理内存状态, 而不必为这个虚拟页分配对应的物理页. 当应用程序访问这个虚拟页时候, 会触发缺页异常, 此时操作系统才真正为这个虚拟页分配对应的物理页, 并且在页表中填入对应的映射. 这种按需分配的机制使得操作系统能够在应用程序真正需要使用物理内存的时候再分配物理页, 能够有效的节约物理内存, 提高资源利用率 在按需分配机制中也存在着一个权衡: 虽然节约了内存资源, 但是对于每个内存页来说, 初次访存时候产生的缺员异常会导致访问延迟增加 (但是, 这一点操作系统可以利用应用程序访存的时空局部性特点来改善问题, 即利用预取机制来进行改善)
[!question] 操作系统如何记录虚拟页分配的状态? 由于应用程序通常使用虚拟地址空间中的一些区域 (比如数据和代码、栈、堆分别对应于三个互不连续的虚拟内存区域), 所以在 Linux 中, 应用程序的虚拟地址空间被实现成由多个虚拟内存区域 (Virtual Memory Area, VMA)组成的数据结构. 每个虚拟内存区域中包含该区域的启示虚拟地址、结束虚拟地址、访问权限等信息. 当应用程序发生缺页异常时候, 操作系统通过判断虚拟页 P 是否须属于该应用程序的某个虚拟内存区域来区分该页所处的分配状态. 若属于, 则说明该页处于已分配但未映射至物理页状态; 若不属于, 则说明该页处于未分配状态.
超越物理内存: 策略
在虚拟内存管理中, 如果拥有大量空闲的内存, 操作就回变得容易. 当也错误发生时候, 只需要在空闲页的列表中找到空闲页, 将它分配给不在内存中的页. 但是, 当内存不足时候, 就会变得复杂, 由于内存的压力, 需要使操作系统换出一些页, 为了确定要提出哪个页, 则需要操作系统实现合理的页面替换策略.
缓存管理
- 由于内存值包含系统中所有页的子集, 因此可以将其视为虚拟内存页的缓存
- 目标: less miss and more hit
- 程序的平均内存访问时间的计算: (\(AMAT=(P_{Hit}\cdot T_M) + (P_{Miss}\cdot T_D)\)\)
- \(T_M\) 访问内存的成本
- \(T_D\) 访问磁盘的成本
- \(P_{Hit}\): 缓存命中的概率
- \(P_{Miss}\): 缓存不命中的概率
[!note] 在现代系统中, 磁盘访问的成本非常高, 即使很小概率的未命中也会拉低正在运行的程序的总体 AMAT. 显然, 我们必须尽可能地避免缓存未命中, 避免程序以磁盘的速度运行 因此, 我们非常需要一个优秀的策略.
最优替换策略
- 简单但是难以实现的最优替换策略: 替换内存中在最远的将来才会被访问到的页
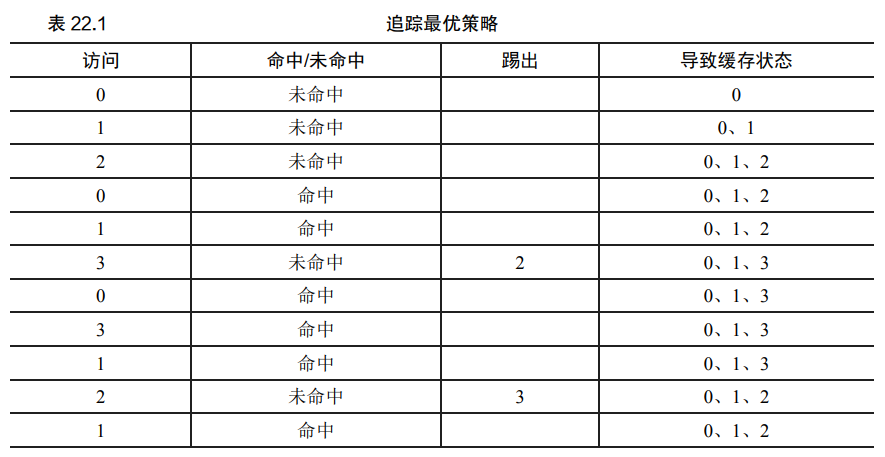
[!note] 缓存未命中的类型 1. 强制性未命中: 程序刚启动时候, 缓存为空, 任何一次的访问, 但是未命中 2. 容量未命中: 由于缓存的空间不足而不得不踢出一个项目以将新项目引入缓存, 就发生了容量未命中 3. 冲突未命中: 由于银奖缓存中对项的放置位置有限制, 这是由于所谓的集合关联性, 它不会出现在操作系统页面缓存中, 因为这样的缓存总是完全关联的, 即对页面可以放置的内存位置没有限制
- 既然难以实现, 为什么要提出这样的最优替换策略: 在开发一个真正的, 可以实现的策略时候, 我们将聚焦于寻找其他决定把哪个页面踢出的方法. 因此, 我们需要将最优策略作为比较, 了解我们的策略有多接近"完美"
简单策略: FIFO
- 简单的设置一个队列, 当发生替换时候, 将队头的页踢出
- 命中率低

另一种简单策略: 随机
- 在内存满的时候随机选择一个页进行替换
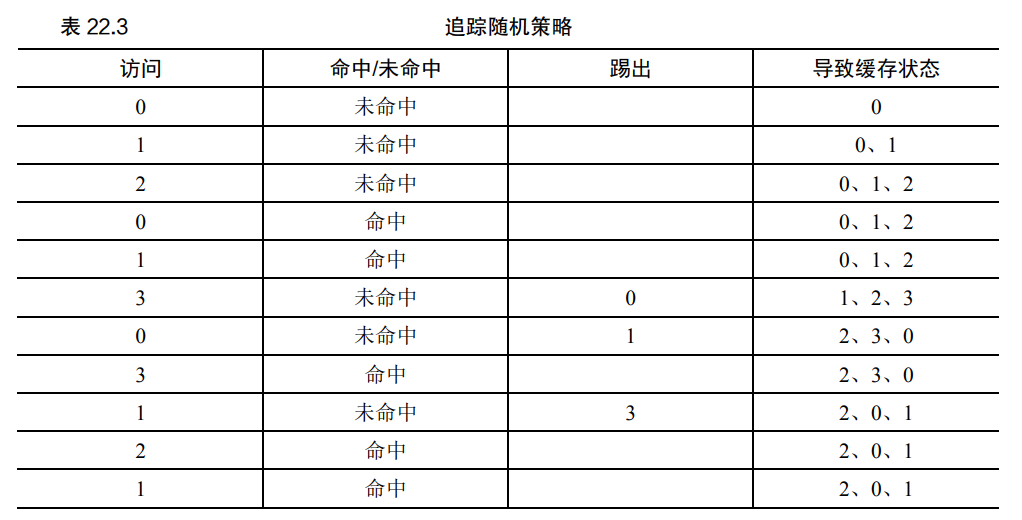
- 具有随机性
利用历史数据: LRU
[!note] 程序的局部性 程序倾向于表现出两种类型的局部: 1. 空间局部性: 如果页 P 被访问, 可能围绕他的页也会被访问 2. 时间局部性: 近期访问过的页面很可能在不久的将来再次访问
利用程序的这类局部性, 可以在硬件层面上帮助程序更快的运行 - 上述两个方法存在的问题: 可能会踢出一个重要的页, 而这个页马上要被引用 - 除了上述的两个方法, 我们还可以利用程序的局部性, 将历史的访问情况作为参考 - 如果一个页被访问了很多次, 则它不应该被替换, 因为它更有价值
- 这样的效果基本接近最优策略
工作负载示例
工作场景一
第一个工作负载没有局部性, 每一次的访问都具有随机性
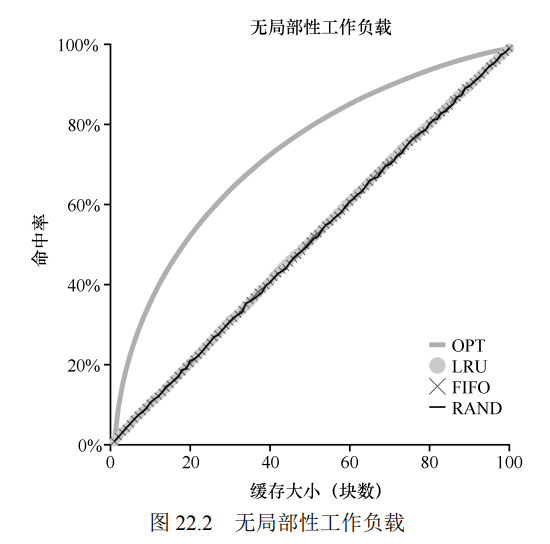 从图中可以看到, 当工作负载不存在局部性时候, 使用任何策略区别都不大.
从图中可以看到, 当工作负载不存在局部性时候, 使用任何策略区别都不大.
工作场景二
第二个工作负载遵循着所谓的"80-20": 80%的引用是访问 20%的页, 20%的引用访问是 80%的页
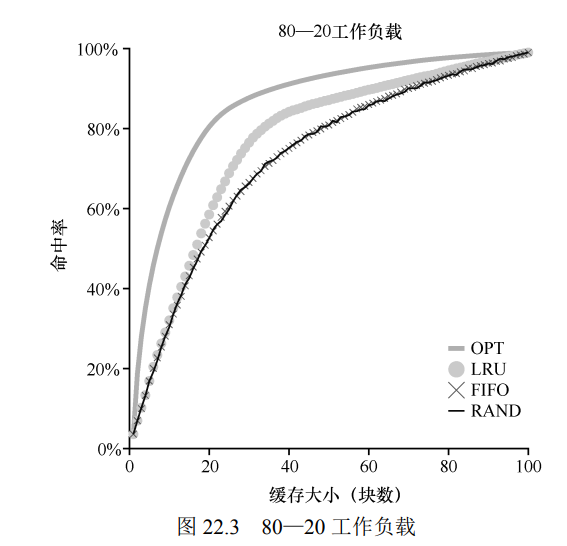 尽管随机和 FIFO 都可以很好的工作, 但是 LRU 的效果显然更好
尽管随机和 FIFO 都可以很好的工作, 但是 LRU 的效果显然更好
第三个工作负载
最后一个工作负载被称为"循环顺序", 其中一次引用 50 个页, 从 0 - 49, 然后再次进行访问, 总共有 10000 次访问 50 个单独页
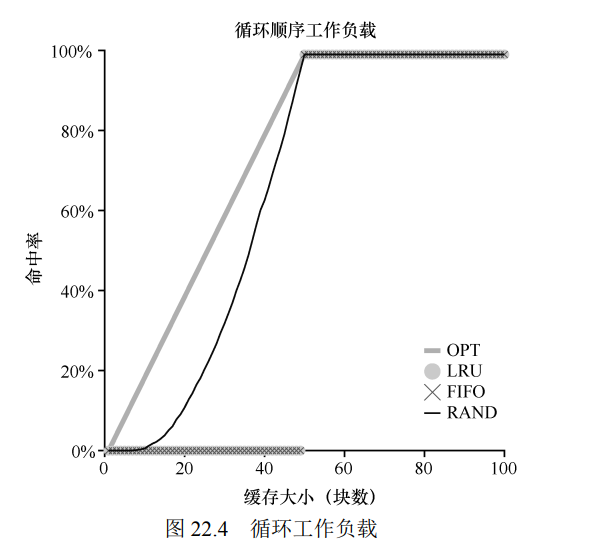 这样的工作负载在许多的应用程序中都非常常见 (数据库应用), 展示了 LRU 或 FIFO 的最差情况
在循环顺序的工作负载下, 踢出较旧的页面
但是, 由于工作负载的循环性质, 这些较旧的页将比因为策略决定保存在缓存中的页更早被访问.
这样的工作负载在许多的应用程序中都非常常见 (数据库应用), 展示了 LRU 或 FIFO 的最差情况
在循环顺序的工作负载下, 踢出较旧的页面
但是, 由于工作负载的循环性质, 这些较旧的页将比因为策略决定保存在缓存中的页更早被访问.
基于历史信息的算法
- 为了实现 LRU, 在每次页访问时候, 我们都必须更新一些数据, 从而将该页移动到列表的前面
- 为了记录哪些页是最少和最近被使用的, 系统必须对每次内存引用做一些记录工作, 而这个过程中, 如果不小心, 会极大的影响性能
- 提高速度的一种方法: 提供硬件支持
- 硬件可以在每个页访问时更新内存中的时间字段, 当页被访问时候, 时间字段将被硬件设置为当前时间, 然后, 在需要替换页的时候, 操作系统可以简单的扫描系统中所有页的时间字段以找到最近最少使用的页
- 但是, 随着页数量的增长, 扫描也的时间也需要花费大量的时间
近似 LRU
- 使用位 (use bit)
- 每当页被引用时, 硬件将使用位设置为 1. 而清零的操作由操作系统负责
- 操作系统的方法: 使用时钟算法
- 系统中的所有页都存放在一个循环列表中. 时钟指针开始时指向某个特定的页. 当必须进行页替换时候, 操作系统检查当前指向的页 P 的使用位. 如果是 1, 则意味着页面 P 最近被使用, 因此不适合被替换, 然后将其设置为 0, 并且指向下一页, 直到找到一个使用位为0的页
考虑脏页
- 对于时钟算法的修改: 检查内存中的页是否被修改过
- 原因: 如果页已经被修改, 则踢出他就必须将其写回磁盘, 这个操作需要付出昂贵的代价. 如果它没有被修改, 踢出就没成本
- 因此, 一些虚拟机系统倾向于踢出干净页
抖动
- 最后一个问题: 当内存被超额请求时候, 操作系统应该做什么, 这组正在运行的进程的内存需求是否超出了可用物理内存? 在这种情况下, 系统将不断的进行换页, 这种情况被称为抖动
- 早期操作系统的应对方法: 给定一组进程, 系统可以决定不运行部分进程, 希望减少的进程工作集能够放入内存, 从而能够去的进展
- 现代操作系统的应对方法: 当内存超额请求时候, 某些版本的 linux 会运行一个守护程序——"out of memory killer 内存不足杀手", 这个守护进程会选择一个内存密集型程序并且杀死
参考
- OSTEP
- 分页: 介绍
- 分页: 快速地址转换
- 分页: 较小的页
- 超越物理内存: 机制
- 超越物理内存: 策略
- 银杏书
- 内存管理
- 基于分页的虚拟内存
- 内存管理