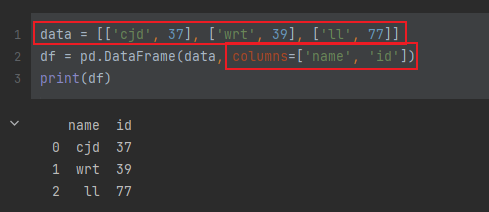
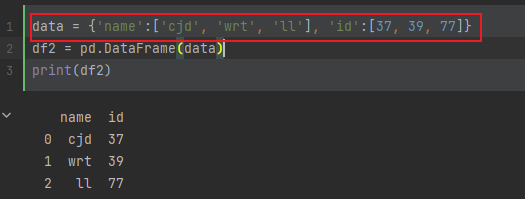
数据结构
Series
Series类似于表格中的一个列,即一个一维数组,可以保存任何数据- 构造函数:
pandas.Series(data, index, dtype, name, copy)
data:一组数据(ndarray类型)index:数据索引标签,不指定则默认从0开始dtype:数据类型,默认自动判断name:设置Series的名称copy:拷贝数据,默认为False
索引(index)
- 可以使用指定的索引值来取出元素:
name[index]
- 自定义索引
- 使用List:
index = ['a', 'b', 'c', ...]
- 同样,可以使用类字典(key/value)的方式来创建
Series
- 可以使用
object.index取出索引
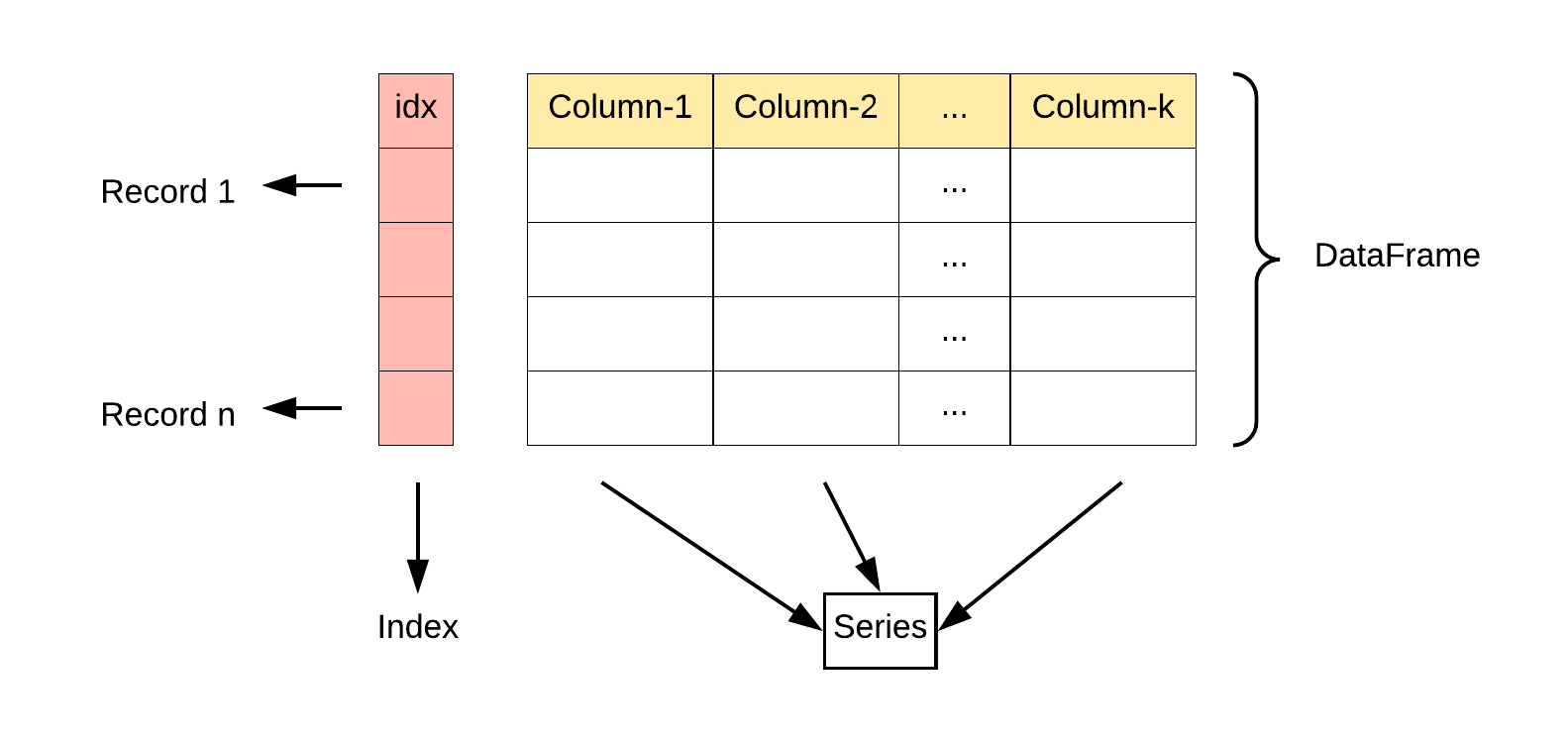
DataFrame
DataFrame是一个表格型的数据结构
- 含有一组有序的列,每列可以是不同的值类型
- 既有行索引,也有列索引
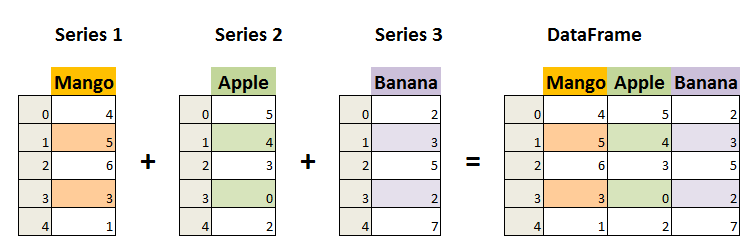
- 可以被看作由Series组成的字典(共用一个索引)
- 构造方法:
pandas.DataFrame(data, index, column, dtype, copy)
- 参数说明
data:一组数据(ndarray/series/map/lists/dict等类型)index:行标签,不指定则默认从0开始column:列标签,不指定则默认从0开始dtype:数据类型,默认自动判断copy:拷贝数据,默认为False
- 使用普通方法构建:
- 使用
ndarray创建
- 使用字典创建,其中字典的key为列名
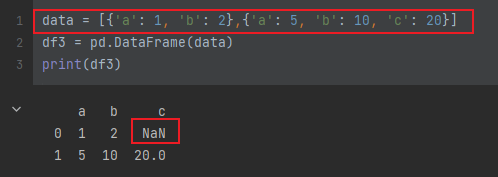
- 没有对应的部分数据为
NaN
索引
- 索引值的指定方法与
Series一致
- 使用
object.object和object.column取出行索引和列索引
loc
- 若没有设置行索引,则默认从0开始:
df.loc[3]
- 使用
[[indexs]]返回多行数据:df.loc[[0,1]]
- 返回的结果为一个
DataFrame数据
- 同样可以使用
[from:to]索引多行
iloc
- 通过普通索引(数字)的方式索引数据
- i->index
- 其返回值附带标签信息
- 条件过滤筛选
df[df["A"]>0]df.loc[:, df.iloc[0] > 0]