PA3-穿越时空的旅程: 批处理系统
穿越时空的旅程
trap.S中的宏展开过程:MAP(REGS, PUSH)MAP(c, f)->c(f)
REGS(PUSH)REGS(f)->REGS_LO16(f) REGS_HI16(f)
REGS_LO16(PUSH) REGS_HI16(PUSH)REG_LO16(f)->f(1) f(3) f(4) ... f(15)REG_HI16(f)->f(16) f(17) ... f(31)
PUSH(1) PUSH(3) PUSH(4) PUSH(5) PUSH(6) ... PUSH(30) PUSH(31)PUSH(n)->STORE concat(x, n), (n * XLEN)(sp);STORE->swconcat(x, n)->xn(n * XLEN)(sp)->(n * 4)(sp)
sw x1, (4)(sp); sw x3, (3 * 4)(sp); sw x4, (4 * 4)(sp); ...; sw x31, (31 * 4)(sp);
- 在
test yield中, 调用ecall后发生了什么:ecall调用isa_raise_intr(11, s -> pc)(ecall的行为) 引发中断, 调转到程序中提前设定好的中断处理函数__am_asm_trap(__am_asm_trap的代码位于trap.S中, 是一段汇编代码)- 在
__am_asm_trap中, 会先保存程序的上下文, 然后调用__am_irq_handle, 在__am_irq_handle会调用cte_init时候设定好的中断处理函数, 在test yield中也就是simple_trap
cte_init初始化了什么?asm volatile("csrw mtvec, %0" : : "r"(__am_asm_trap)): 设定mtvec这个 csr 寄存器的值为函数__am_asm_trap的地址,mtvec是异常入口地址, 在发生异常或陷入时候会调用mtvec所指向的函数进行处理user_handle = handler: 设定异常处理的回调函数, 这个回调函数会在__am_asm_trap中调用__am_irq_handle时候被调用以处理异常
__am_asm_trap做了什么?- 分配栈空间, 将上下文信息保存在栈中 (
Context) - 将被分配到的栈空间的起始地址作为
__am_asm_handle的参数, 并调用__am_asm_handle, 在__am_asm_handle中将会对上下文信息进行处理 - 返回后, 将上下文信息恢复, 释放栈帧, 并且调用
mret返回
- 分配栈空间, 将上下文信息保存在栈中 (
- 为什么要实现正确的上下文信息的存储顺序?
- 在
trap.S中实现的__am_asm_trap中所实现的入栈顺序是已经固定下来, 并且将分配到的栈空间的起始地址作为__am_asm_handle的参数struct Context进行调用, 如果实现了错误的顺序, 在__am_asm_handle中通过偏移量获得的数据将会出现混乱的情况, 因此需要按照入栈的顺序来实现Context中成员的顺序
- 在
用户程序和系统调用
加载第一个用户程序
- 堆和栈在哪里? 为什么堆和栈的内容没有放入可执行文件中?
- 因为堆和栈属于运行时, 在编译时是无法知道其中的数据的, 而编译时的结果是可执行文件, 自然, 可执行文件中就不会有堆和栈的内容, 只有到了运行时, 才会分配空间给程序,
- 堆与栈的具体位置可以看
abstract-matchine/scripts/linker.ld链接脚本, 这个链接脚本非常明确的指出的程序运行时各个段的大小和范围, 且在PHDRS中指定了哪些段用于生成最后的可执行文件
为什么堆和栈的内容没有放入可执行文件中? 在看 linker.ld 时候, 可以发现在第 2 行的链接脚本: PHDRS { text PT_LOAD; data PT_LOAD;}, 这行是被链接器用来控制最后的可执行文件中有什么.
PHDRS 指令用来定义程序头 (program header), 他们描述了节 (section)应该如何被加载到内存中, 在这个链接脚本中, 定义了两个 PT_LOAD 类型的段: text 和 data, 分别用于存储代码和数据, 且分别对应了 .text 节和 .data, .bss 节. PT_LOAD 段类型表示在程序运行时候, 这两个段要被加载到内存中去.
[!note] refer - copilot This line of code is part of a linker script, which is used by the GNU linker to control the process of creating the final executable file from several object files. The
PHDRScommand is used to define program headers. Program headers are part of the ELF (Executable and Linkable Format) binary format used on Unix and Unix-like systems. They describe how sections of the binary should be loaded into memory when the program is run. In this case, two program headers are being defined:textanddata. Both are being associated with thePT_LOADsegment type. ThePT_LOADsegment type indicates that these sections should be loaded into memory when the program is run. Thetextprogram header typically corresponds to the.textsection of the binary, which contains the executable code. Thedataprogram header typically corresponds to the.dataand.bsssections, which contain initialized and uninitialized data respectively. In summary, this line of code is instructing the linker to create two program headers in the final binary, one for the code (text) and one for the data (data), and to load both sections into memory when the program is run.
elf 文件提供了两个视角来组织一个可执行文件, 一个面向链接过程的 section 视角, 这个视角提供了用于链接与重定位的信息; 另外一个是面向执行的 segment 视角, 这个视角提供了用于加载可执行文件的信息.
通过 readelf 命令, 就可以看到 section 和 segment 之间的映射关系, 比如查看 cpu-tests/wanshu 的 elf 文件, 它的映射关系如下: 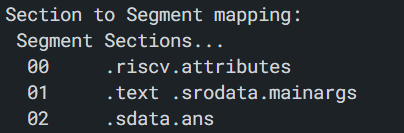 可以看到, 一个段 (segment)可以包含不止一个节 (section), 且一个节可能不被任何一个段包含.
现在我们关系的是如何加载程序, 因此关注的重点是
可以看到, 一个段 (segment)可以包含不止一个节 (section), 且一个节可能不被任何一个段包含.
现在我们关系的是如何加载程序, 因此关注的重点是 segment 视角. ELF 中采用 Program Header Table 来管理 segment, Program Header Table 的一个表项描述了一个 segment 的所有属性, 包括类型, 虚拟地址, 标志和对齐方式, 以及文件内偏移量和 segment 的大小.
根据这些信息, 我们就可以知道需要加载可执行文件的哪些字节了, 我们就是通过判断 segment 的 Type 属性是否为 PT_LOAD 来判断一个 segment 是否需要被加载.
通过观察 segment 所包含的两个大小属性: FileSiz 和 MemSiz, 为什么包含两个大小属性? 为什么 FileSiz 通常不大于相应的 MemSiz?
 我们通过了解可执行文件是如何被加载的就可以知道答案了:
我们通过了解可执行文件是如何被加载的就可以知道答案了:
+-------+---------------+-----------------------+
| |...............| |
| |...............| | ELF file
| |...............| |
+-------+---------------+-----------------------+
0 ^ |
|<------+------>|
| | |
| |
| +----------------------------+
| |
Type | Offset VirtAddr PhysAddr |FileSiz MemSiz Flg Align
LOAD +-- 0x001000 0x03000000 0x03000000 +0x1d600 0x27240 RWE 0x1000
| | |
| +-------------------+ |
| | |
| | | | |
| | | | |
| | +-----------+ --- |
| | |00000000000| ^ |
| | --- |00000000000| | |
| | ^ |...........| | |
| | | |...........| +------+
| +--+ |...........| |
| | |...........| |
| v |...........| v
+-------> +-----------+ ---
| |
| |
Memory
Offset, VirtAddr, FileSiz 和 MemSiz. 然后从可执行文件的 Offset 处找出大小为 FileSiz 的段, 并加载到以 VirtAddr 为首地址的虚拟内存位置, 且占用大小为 MemSiz, 然后需要将 [VirtAddr + FileSiz, VirtAddr + Memsiz) 对应的内存区域清零, 避免在读取时候读取到脏数据, MemSiz > FileSiz 的原因是段存储在文件中, 只需要记录好偏移量即可, 不需要考虑对齐和页, 而加载到内存后, 需要进行对齐, 且由于不属于同一个段, 自然就不属于同一个页, 其中就可能会出现一段空白区域, 则所占用的 MemSiz 就会大于 FileSiz
[!note] refer - 用户程序和系统调用 | 官方文档
- 程序运行时刻用到的堆和栈是怎么来的?
- 堆: 由 am 直接分配 (
abstract-machine/am/src/platform/nemu/trm.c:7) - 栈: 在 am 中"手动"开辟一块内存空间 (
abstract-machine/am/src/riscv/nemu/start.S:7)
- 堆: 由 am 直接分配 (
- GNU 是如何知道格式错误的?
- 在 ELF 文件的开头有一个 MagicNumber, 通过识别这个 Magic Number, 就可以知道读入的文件是不是 elf 文件
- 必答题: hello 程序是什么? 它从何而来? 要到哪里去?
- 在
navy-apps/tests/hello目录下进行编译过后, 生成 elf 文件 (这个过程与编译 am 上的程序类似, 对每个文件进行编译, 再将生成的.o文件进行链接, 生成最后的可执行文件, 至于代码段的开始位置, 在navy-apps/tests/scripts/riscv/common.mk中设置, 将其设置为0x83000000是为了与操作系统 nanos-lite 所装载的位置0x80000000区分开来, 也就是说0x80000000~0x82ffffff这部分区域的代码都是操作系统的代码) hello的程序代码在生成后, 拷贝到nanos-lite/build/ramdisk.img, 并且以二进制的形式被载入到resources.S中, 在 nanos-lite 中通过调用loader函数, 将其从 ramdisk 区域加载到目标区域上, 这个区域由 elf 文件中的Program Headers中的Offset,VirtAddr,FileSiz和MemSiz决定, 具体的装载过程见上文- 在装载过后, 跳转到 elf 文件中指定的 entry, 开始执行
hello程序 (用户程序) - 在
hello程序中调用printf的时候, 会调用write系统调用进行输出:nanos-lite在初始化时候, 会设置do_syscall作为异常处理的入口- 调用
printf, 最终会调用_write以调用_syscall_(SYS_write, fd, buf, count)进行系统调用 - 在
_syscall_会设置好系统调用的各项参数, 最后调用ecall自陷, 进入系统程序, 即异常的处理过程, 识别出是系统调用并包装后, 调用do_syscall, 对指定的系统调用进行处理 (如何跳转到do_syscall请见 PA3.1 部分的笔记: 调用ecall后发生了什么) - 在
do_syscall中, 识别出调用号为SYS_write后, 调用sys_write进行处理, 其中, 调用putch向串口输出字符 - 调用
putch后, am 会将字符写入到串口的外设地址上, 在调用paddr_write时候识别出写目标地址是一个外设地址, 则会调用mmio_write获取目标映射(map), 再调用map_write向外设地址中写入数据, 并调用设置的回调函数, 进行处理, 对于串口外设, 即在回调函数中调用putch进行输出 (此putch与先前提到的putch不能混淆, 这里的putch是 linux 系统提供), 至此, 完成了一个字符的输出
- 完成系统调用
write后, 返回输出的字符数 (这里的返回是通过向上下文中的a0寄存器写入值, 在后续恢复寄存器后, 用户程序就可以直接从a0获得此次系统调用的返回了)
- 在
精彩纷呈的应用程序
更丰富的运行时环境
- 为什么
fixedpt_rconst()具有明显的浮点操作, 但是从编译的结果来看却没有任何的浮点指令?- 宏在编译前就可以展开, 在编译时就可以得到运算的结果, 因此, 在运行时看来, 这个数就是一个
fixedpt
- 宏在编译前就可以展开, 在编译时就可以得到运算的结果, 因此, 在运行时看来, 这个数就是一个
- 神奇的
LD_PRELOAD: 使用LD_PRELOAD可以达到偷天换日的效果, 可以在主程序和其动态连接库之间加载其他的动态链接库- 如果我们想要使用自己实现的库函数, 则可以使用
LD_PRELOAD实现
- 如果我们想要使用自己实现的库函数, 则可以使用